利用Scrapy爬取网站
前言
毕设可能是弄爬虫,学个框架
学习文档:
Scrapy 2.7 documentation — Scrapy 2.7.1 documentation
Python Scrapy爬虫框架详解 (biancheng.net)
安装scrapy
我直接pycharm软件包装上了,也可以参考说明文档
开始
创建项目
终端输入:
scrapy startproject [项目名]
会在当前目录下创建一个以输入的目录名为名的文件夹
项目名/
├──scrapy.cfg # 项目基本配置文件
├──项目名/ # 装载项目文件的目录
├── __init__.py
├── items.py # 项目项定义文件,定义要抓取的数据结构
├── middlewares.py # 项目中间件文件,用来设置一些处理规则
├── pipelines.py # 项目管道文件,处理抓取的数据
├── settings.py # 项目全局配置文件
├── spiders/ # 装载爬虫文件的目录
├── __init__.py # 具体的爬虫程序
生成爬虫
生成项目后,cd 进入项目所在目录 (创建爬虫文件 注意url 一定要是网站域名)
scrapy genspider example example.com
这里以起点中文网为例:
scrapy genspider qidian qidian.com
会在目录spiders 生成文件qidian.py,代码如下:
import scrapy
class QidianSpider(scrapy.Spider):
name = 'qidian'
allowed_domains = ['qidian.com'] #要抓取数据的网站域名
start_urls = ['http://qidian.com/'] #第一个抓取的url,初始url,被当做队列来处理
def parse(self, response):
pass
注:这里的start_urls作为列表形式,爬取时只需将要爬取的url都存进去即可,可以利用以往的start_requests方法来构建
运行爬虫
可以用命令crawl运行,也可以利用pycharm来运行
为了省去终端敲命令的环节,您可以在项目中自定义一个运行文件 main.py(注意:该文件与 scrapy.cfg 同目录),并编写如下代码:
from scrapy import cmdline
# 注意,cmdline.execute()是为了减少输入命令的操作,该方法的参数必须为列表。
# 执行爬虫文件来启动项目
cmdline.execute('scrapy crawl title'.split())
常用指令
命令 格式 说明 startproject scrapy startproject <项目名> 创建一个新项目。 genspider scrapy genspider <爬虫文件名> <域名> 新建爬虫文件。 runspider scrapy runspider <爬虫文件> 运行一个爬虫文件,不需要创建项目。 crawl scrapy crawl <爬虫项目名> 运行一个爬虫项目,必须要创建项目。 list scrapy list 列出项目中所有爬虫文件。 view scrapy view <url地址> 从浏览器中打开 url 地址。 shell csrapy shell <url地址> 命令行交互模式。 settings scrapy settings 查看当前项目的配置信息。
实战
还是用起点中文网练手
创建项目和爬虫文件
scrapy startproject qidian
cd qidian
scrapy genspider qidian qidian.com
定义数据结构
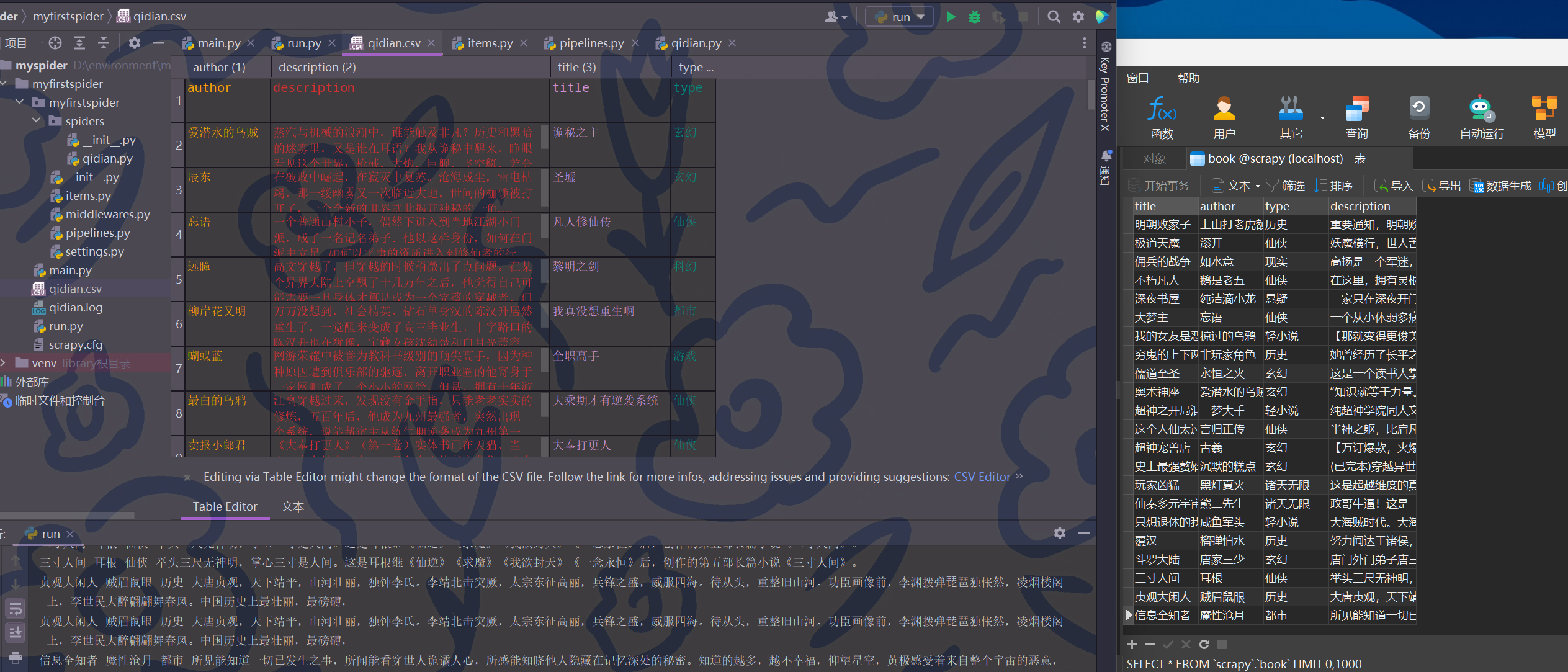
在items.py中定义数据结构,这次要抓取小说名、作者、小说类型和描述
title = scrapy.Field()
author = scrapy.Field()
type = scrapy.Field()
description = scrapy.Field()
编写爬虫文件qidian.py
import scrapy
from ..items import MyfirstspiderItem
class QidianSpider(scrapy.Spider):
name = 'qidian'
allowed_domains = ['qidian.com'] #要抓取数据的网站域名
start_urls = [] #第一个抓取的url,初始url,被当做队列来处理
for i in range(1, 6):
start_urls.append('https://www.qidian.com/finish/page{}/'.format(i))
def parse(self, response):
book_list = response.xpath('//div[@class="book-mid-info"]')
item = MyfirstspiderItem()
for book in book_list:
item['title'] = book.xpath('./h2/a/text()').get().strip()
item['author'] = book.xpath('./p[@class="author"]/a/text()').get().strip()
item['type'] = book.xpath('./p[@class="author"]/a[2]/text()').get().strip()
item['description'] = book.xpath('./p[@class="intro"]/text()').get().strip()
# print(item['title'], item['author'], item['type'], item['description'])
yield item
数据存储
通过编写管道文件 pipelinse.py 文件实现数据的存储,将抓取的数据存放在 MySQL 数据库 (需要提前建库、建表)
import pymysql
from .settings import *
class MyfirstspiderPipeline:
def process_item(self, item, spider):
print(item['title'], item['author'], item['type'], item['description'])
return item
# 存入mysql数据库的管道
class MyfirstspiderMysqlPipeline:
def open_spider(self, spider):
# 爬虫项目启动,执行连接数据操作
# 以下常量需要定义在settings配置文件中
self.db = pymysql.connect(
host=MYSQL_HOST,
user=MYSQL_USER,
password=MYSQL_PWD,
database=MYSQL_DB,
charset=MYSQL_CHARSET
)
self.cursor = self.db.cursor()
# 向表中插入数据
def process_item(self, item, spider):
ins = 'insert into book values(%s,%s,%s,%s)'
L = [
item['title'], item['author'], item['type'], item['description']
]
self.cursor.execute(ins, L)
self.db.commit()
return item
# 结束存放数据,在项目最后一步执行
def close_spider(self, spider):
# close_spider()函数只在所有数据抓取完毕后执行一次,
self.cursor.close()
self.db.close()
print('执行了close_spider方法,项目已经关闭')
修改配置文件
添加日志输出、激活管道 pipelines、定义数据库常量,以及其他一些常用选项,如下所示:
#设置 robots.txt 为False
ROBOTSTXT_OBEY = False
#设置日志级别: DEBUG < INFO < WARNING < ERROR < CRITICAL
#日志需要自己添加,配置文件中没有,在空白处添加即可
LOG_LEVEL='DEBUG'
#定义日志输出文件
LOG_FILE='qidian.log'
#设置导出数据的编码格式
FEED_EXPORT_ENCODING='utf-8'
#设置下载器延迟时间,秒为单位
DOWNLOAD_DELAY = 1
#请求头,添加useragent等信息
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1'
}
#激活管道,并添加数据存放mysql的类,200为执行优先级
ITEM_PIPELINES = {
'myfirstspider.pipelines.MyfirstspiderPipeline': 300,
# 执行数据存储mysql
'myfirstspider.pipelines.MyfirstspiderMysqlPipeline': 200,
}
#在配置文件末尾添加mysql常用变量
MYSQL_HOST='localhost'
MYSQL_USER='root'
MYSQL_PWD='123456'
MYSQL_DB='scrapy'
MYSQL_CHARSET='utf8'
定义启动文件
下面定义项目启动文件 run.py, 代码如下:
from scrapy import cmdline
#执行爬虫文件 -o 指定输出文件的格式
cmdline.execute('scrapy crawl qidian -o qidian.csv'.split()) #执行项目,并且将数据存csv文件格式